УДК 004.043:004.89
МЕТОДЫ ХРАНЕНИЯ И ОБРАБОТКИ НЕЧЕТКИХ ДАННЫХ В СРЕДЕ РЕЛЯЦИОННЫХ СИСТЕМ
Касаткина Н.В., Танянский С.С., Филатов В.А.
Введение
Математическая теория нечетких множеств (fuzzy sets) и нечеткая логика (fuzzy logic) продолжают привлекать внимание исследователей в области интеллектуальных, экспертных систем, а также систем поддержки принятия решений. Эти понятия были впервые предложены американским ученым Лотфи Заде (Lotfi Zadeh). Основной причиной появления новой теории стало наличие нечетких и приближенных рассуждений при описании человеком процессов, систем, объектов.
Нечеткий подход к моделированию сложных систем получил признание во всем мире, прошло не одно десятилетие с момента зарождения теории нечетких множеств. И на этом пути развития нечетких систем принято выделять несколько периодов. Первый период (конец 60-х – начало 70 гг.) характеризуется развитием теоретического аппарата нечетких множеств (Л.Заде, Э.Мамдани). Во втором периоде (70–80-е годы) появляются первые практические результаты в области нечеткого управления сложными техническими системами. Одновременно внимание уделялось разработке экспертных систем, построенных на нечеткой логике, и нечетких контроллеров. Нечеткие экспертные системы для поддержки принятия решений находят широкое применение в медицине и экономике. Наконец, в третьем периоде, который длится с конца 80-х годов и продолжается в настоящее время, появляются пакеты программ для построения нечетких экспертных систем, а области применения нечеткой логики заметно расширяются. Она применяется в автомобильной, аэрокосмической и транспортной промышленности, в сфере финансов, анализа и принятия управленческих решений и многих других.
В последнее десятилетие отмечается гибридизация методов интеллектуальной обработки информации. Мягкие вычисления объединяют такие области как нечеткая логика, искусственные нейронные сети, извлечение знаний, базы данных, вероятностные рассуждения, эволюционные алгоритмы и ряд других. Они дополняют друг друга и используются в различных комбинациях для создания гибридных интеллектуальных систем.
Не остались в стороне от интересного и современного направления исследователи в области баз данных. Разрабатывается нечеткая реляционная алгебра и специальные расширения структурированного языка (SQL) для нечетких запросов. В этой области интенсивные исследования проводят европейские ученые Д.Дюбуа и Г.Праде. Формируется перспективное направление в современных системах обработки информации – нечеткие запросы к базам данных (fuzzy queries).
В этом контексте можно рассматривать два основных вопроса, наиболее актуальных в настоящее время: (1) как проектировать, (2) где и в каких структурах хранить нечеткие данные систем такого класса.
Решение этих проблем откроет пути интеграции накопивших колоссальные объемы информации реляционных баз данных и систем на основе нечеткой логики.
Целью проводимых исследований является разработка методов хранения и обработки нечетких данных средствами реляционной модели, ориентированной на реализацию в среде современных систем управления базами данных (СУБД). Особое внимание уделено обоснованию выбора схемы реляционной модели данных для представления функций принадлежности лингвистических переменных.
Основные свойства реляционной модели
Рассмотрим классический подход к построению реляционного отношения, предложенный Э.Коддом [1], и выделим основные свойства отношений при расширении множества доменов.
Основной структурной компонентой данных в реляционной модели данных (РМД) является n-арное отношение, представляющее собой подмножество кортежей декартова произведения доменов, то есть множества значений элементов данных. Для заданных конечных множеств D1,…, Dn (не обязательно различных по типу) декартовым произведением D1´…´ Dn называется множество произведений вида d1,…, dn, где d1ÎD1,…, dnÎDn.
Отношением R, определенным на множествах D1,…, Dn, называется подмножество произведения (декартово произведение) D1´…´ Dn, то есть R Í D1´D2´…´Dn.
Множество D = {D1,…, Dn} называется доменом. Домены – это однотипные семантически однозначные (одинаковые по смыслу) значения элементов данных. Элементы декартова произведения d1,…, dn называются кортежами, число n определяет степень отношения; количество кортежей определяет мощность отношения.
Пусть a = {a1,…, an} – множество имен, тогда введем однозначное отображение вида r : ai ® Di , где пару Ai = < r (ai), Di > называют атрибутами отношения.
Схемой отношения R будем называть выражение S (A1,…, An) в котором все атрибуты Ai различны. При этом экземпляр отношения R(S) определяется как подмножество декартова произведения доменов ri Í r(ai) ´…´ r(an). Экземпляр отношения со схемой Ri будем обозначать как Ri (ri). Отметим, что перестановка атрибутов в схеме не порождает нового состояния БД. Таким образом, множество атрибутов {A1,…, An} задает тип отношения и определяет его свойства.
Схему БД будем обозначать как множество схем отношений U = {R1,…, Rn}, где Ri Î R и все Ri различны. Соответственно, экземпляр БД будем обозначать множеством экземпляров отношений U (r1,…,rn).
Концептуально реляционная БД является информационной моделью предметной области (ПО), такой, что каждый экземпляр соответствует некоторому состоянию ПО в определенный момент времени. Каждое состояние моделируется упорядоченной совокупностью значений элементов данных, соответствующих значениям свойств объектов ПО. Объекту определенного типа соответствует кортеж отношения [2].
Структура фаззифицированного отношения
Для задач анализа данных определим дополнительный тип отношений, определяющий принадлежность существующих данных к некоторому заданному числовому отрезку, определяющему характеристику рассматриваемого информационного объекта.
Любую линию на координатной плоскости можно представить в виде бинарного отношения, где Dom R описывается значениями оси абсцисс, а Im R описывается значениями оси ординат. В задаче фаззификации диаграмма содержит три показателя, которые необходимо учитывать при формировании отношения.
Будем понимать под нечеткой переменной набор (N, X, Y), где N – это название переменной, X – область рассуждений, Y – нечеткое множество на X. Используя такое определение, зададим три домена, соответствующих элементам переменной [3].
Пусть N = {n1,…, nm}, Y = {0, 0.1,…, 1}, X = {x0,…, xk}. Значения X и Y соответствуют выбранной шкале дискретизации координатных осей и описывают область принадлежности к параметру N. Для каждого параметра N делаем выборку данных по значениям X и строим диаграмму принадлежности, имеющую вид, представленный на рис. 1.
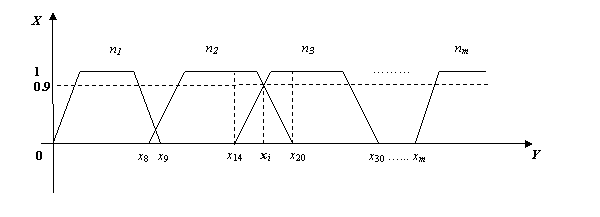
Рис. 1 Распределение количества защит диссертаций по регионам
Для рассмотренного случая определим соответствующие домены для представления нечеткой переменной.
D1 = {n1, n2, n3,…, nm};
D2 = {x0,…, x8, x9,…, x14,…, xi,…, x20,…, x30,…, xm};
D3 = {0, 0.1,…, 1}.
Зададим множество имен доменов и построим отображение. Для множества имен A = {A1, A2, A3} отображение r : (A1 ® D1; A2 ® D2; A3 ® D3) определит множество атрибутов A = {A1, A2, A3} и соответствующую схему отношения S(A1, A2, A3).
Возможные пересечения диаграмм фаззификации определяют тот факт, что все значения могут повторяться относительно друг друга. Например, рассмотрим фрагмент отношения для показателей {x14, xi, x20} представленный на рис. 2.
|
A1 |
A2 |
A3 |
|
n2 |
x14 |
0 |
|
n3 |
x14 |
1 |
|
n2 |
xi |
0.9 |
|
n3 |
xi |
0.9 |
|
n2 |
x20 |
1 |
|
n3 |
x20 |
0 |
|
… |
… |
… |
Рис. 2 - Фрагмент данных для выбранных показателей.
Таким образом, можно говорить об отношении, включающем полный набор кортежей декартова произведения доменов D1´D2´D3 (полное декартово произведение, в данном случае, определяется конечностью значений системы координат). Исходя из этого факта, можно заключить, что ключом отношения будет множество всех атрибутов K = {A1, A2, A3}.
Очевидно, что информативность кортежей определяется значениями на диаграмме фаззификации. Исходя из рассматриваемой задачи, необходимо учитывать еще один показатель – множество значений выборки из БД, для которой строится диаграмма. То есть необходимо установить связь между доменом отношения R f, отражающим значения оси абсцисс и доменом из БД, содержащим значения параметров фаззификации.
Таким образом, следующая задача, которую необходимо рассмотреть, связана с интеграцией отношения R f с БД, хранящей основные показатели.
Обработка параметров фаззификации
Рассмотрим задачу в общем виде. Пусть U (R1,…, Rn) – БД, хранящая основные данные, R f(A1, A2, A3) – отношение фаззификации. Задача будет иметь смысл, если в БД U существует параметр, относительно которого выполнена фаззификация.
Чтобы организовать совместную работу с базами данных U и R, формализуем процедуру интеграции, опираясь на поэтапную нормализацию. Структура БД U получена на основании функциональных зависимостей F = {Mi ® Ni} где Mi, Ni Î U. Выделим одну зависимость, которая включает атрибут с параметрами фаззификации, и обозначим ее как W ® V, причем W и V могут быть множествами. Отношение R f содержит одну зависимость вида F¢ = {A1, A2, A3 ® A1, A2, A3}. Опираясь на аксиомы вывода, можно получить эквивалентное множество F¢ = {A1, A2, A3 ® A1; A1, A2, A3 ® A2; A1, A2, A3 ® A3}.
Пусть параметр фаззификации соответствует атрибуту A2, тогда для определения типа связи необходимо получить множество F = F È F¢ и рассмотреть два случая, влияющих на правила нормализации.
1. A2 Î W – поиск неполных зависимостей: если выполняются функциональные зависимости x ® z и w ® z, причем w Í x, тогда зависимость w ® z является неполной.
2. A2 Î V – поиск транзитивно зависимых элементов: если выполняются функциональные зависимости x ® w и w ® z, тогда элемент z является транзитивно зависимым.
Существование таких зависимостей позволит выполнить корректную декомпозицию и установить связь между базой данных U и R f.
Если A2 = W или A2 = V, то процесс декомпозиции приводит ко второй или третьей нормальной форме. Если равенства не выполняются, то организовать поддержку однозначности связных данных нельзя, так как ассоциация между отношениями будет соответствовать типу «многие-ко-многим».
Как правило, на практике условия равенства не выполняются и для нормализации необходимо выделить базис F и повторить процедуру декомпозиции. Учитывая тот факт, что структура БД не должна изменяться, необходимо связать отношение фаззификации R f и БД U без реструктуризации схемы данных. Используя диаграмму модели «сущность-связь», представим R f и U в виде сущностей (рис. 3).
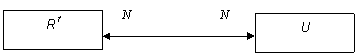 |
Рис. 3 Диаграмма «сущность-связь» между БД U и R f
Для устранения связи “N:N” введем дополнительную связующую сущность, которая решит проблему целостности данных за счет определения новых типов связей. Такая сущность будет содержать один атрибут – связующий для R f и U, причем по объективным причинам он будет ключевым. На рис. 4 показана диаграмма интеграции БД и отношения фаззификации с поддержкой однозначности связи.
 |
Рис. 4 Устранение связи «многие-ко-многим»
Исходя из описания концептуальной схемы ПО видно, что для корректного соединения R f и U необходимо построить промежуточную таблицу. Такой подход гарантирует согласованность данных для любых типов параметров фаззификации.
Покажем, что для рассматриваемой задачи вполне корректны результаты при выполнении соединения отношений с ассоциацией типа “N:N”. Возможные значения атрибута A1 Î U могут повторяться столько раз, сколько данное значение пересекает границы диаграммы фаззификации по оси ординат (см. рис. 1). То есть каждому значению атрибута A1 соответствует строка уникальных данных. Если A1 не является ключом, и значения повторяются, то, по определению множества, в строке должно быть хотя бы одно отличное значение. В терминах решаемой задачи необходимо анализировать все такие строки. В атрибуте A1 отношения R f также повторяются значения, которые необходимо проанализировать, причем во всевозможных комбинациях.
Таким образом, в общем виде для анализа данных, накапливаемых в реляционных базах данных, достаточно построить фаззифицированное отношение и установить связь с атрибутом (атрибутами), по значениям которого необходимо провести соответствующий анализ.
Пример
Для иллюстрации разработанного подхода рассмотрим пример построения интегрированной информационной системы, объединяющей в себе реляционную базу данных и подсистему на основе нечеткой логики.
В 1999 году для Высшей аттестационной комиссии Украины (ВАК Украины) была разработана информационная система обработки, хранения и анализа учетных карточек соискателей на присуждение ученых степеней кандидата или доктора наук. Схема реляционной базы данных включает ряд атрибутов, в том числе:
- фамилия, имя, отчество соискателя,
- дата рождения,
- область наук,
- специализированный совет, где проводилась защита диссертации,
- город, где расположен специализированный совет,
- дата защиты диссертации и ряд других атрибутов.
За время эксплуатации информационная система «ВАК Украины» показала свою эффективность и надежность. В настоящее время база данных насчитывает около 45000 записей. Каждый кортеж в базе данных - это сведения о соискателе, его диссертационной работе, месте и времени защиты. Таким образом, база данных содержит скрытые знания о данной предметной области. Применив технологию запросов к базе данных с использованием стандартных операций – группировки (GROUP), подсчета количества записей (COUNT), подсчета суммы (SUMM), определения максимального (MAX) и минимального значения (MIN) можно определить некоторые закономерности предметной области, относящиеся к категории скрытых знаний [4].
Количество соискателей, претендующих на ученую степень кандидата технических наук с 1999 по 2008 год, представлено на рис. 5.
Использование технологии запросов с применением функции фильтрации позволяют пользователю получать разнообразные статистические данные, аналогичные рассмотренному выше примеру.
Исследования в области мягких вычислений и технология представления функций принадлежности лингвистических переменных средствами реляционной модели, подробно рассмотренные в данной статье, позволяют проводить анализ данных в разрезе нечетких запросов типа «БОЛЬШЕ», «МЕНЬШЕ», «СТАРЫЙ», «МОЛОДОЙ» и т.д.
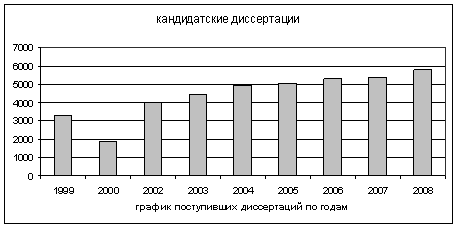
Рис. 5 Поступление в ВАК кандидатских диссертаций по годам
Рассмотрим пример формирования и реализации средствами реляционной СУБД подсистемы нечеткого анализа в терминах «МОЛОДОЙ», «ЗРЕЛЫЙ» и «СТАРЫЙ» кандидат технических наук. Возраст будем определять на дату защиты диссертации. Этот атрибут «Возраст Защиты» может быть легко получен в результате вычитания и простого преобразования двух дат из базы данных «ВАК Украины»: «Дата рождения» и «Дата защиты».
Функции принадлежности лингвистической переменной «ВОЗРАСТ» будут иметь вид, представленный на рис. 6.
 |
Для хранения всех данных лингвистической переменной «ВОЗРАСТ» проектируется отношение с тремя атрибутами: «Годы», «Имя Переменной», «Значение функции принадлежности». Все атрибуты будут объединены в тройной составной ключ. Атрибут «Имя Переменной» предназначен для хранения повторяющихся групп лингвистической переменной «ВОЗРАСТ» - {«МОЛОДОЙ», «ЗРЕЛЫЙ», «СТАРЫЙ»}, поэтому для хранения уникальных значений проектируется отдельное отношение – «Справочник подмножеств» (С_Подмножеств). Следующим этапом построения общей схемы базы данных необходимо создать связь между атрибутами «Возраст Защиты» отношения «Соискатели» базы данных «ВАК Украины» и атрибутом «Годы» отношения «Возраст» Схема интегрированной базы данных приведена на рис. 7.
Модифицированная реляционная модель данных, рассмотренной информационно-аналитической системы, позволяет выполнять нечеткие запросы в терминах «МОЛОДОЙ», «ЗРЕЛЫЙ», «СТАРЫЙ» кандидат наук в сочетании с детерминированными четкими значениями базы данных. Например: определить при помощи запроса, с каким значением функции принадлежности по переменным «МОЛОДОЙ», «ЗРЕЛЫЙ», «СТАРЫЙ» защищаются соискатели в области научных исследований – технические науки. Результат выполнения запроса представлен на рис. 8.
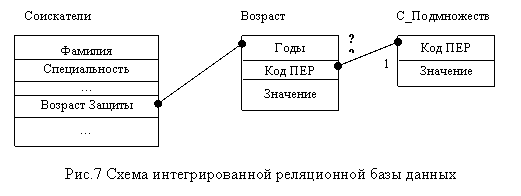 |
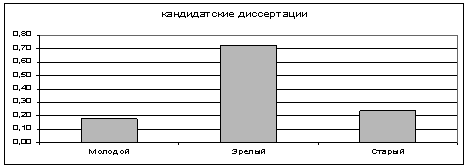
Рис.8 Распределение по категориям «МОЛОДОЙ», «ЗРЕЛЫЙ», «СТАРЫЙ»
Выводы
Статья посвящена исследованию методов и структур хранения и обработки нечетких данных средствами реляционного представления и моделирования с ориентацией на реализацию в среде современных СУБД. Особое внимание уделено обоснованию выбора схемы реляционной модели данных для представления функций принадлежности лингвистических переменных. Реляционная модель представления и реализации нечетких моделей может стать связующим звеном для интеграции с существующими реляционными базами данных. Это позволит получить новый инструмент для извлечения новых ранее недоступных данных и знаний. Приведен пример, подтверждающий эффективность разработанного подхода.
ЛИТЕРАТУРА
1. Мейер Д. Теория реляционных баз данных: Пер. с англ. – М.: Мир, 1987. – 608 с.
2. Конноли Т., Бегг К. Базы данных: проектирование, реализация и сопровождение. Теория и практика, 2-е изд.: Пер с англ. - М.: «Вильямс», 2000. - 1120 с.
3. Гибридные нейро-фаззи модели и мультиагентные технологии в сложных системах: монография / В.А. Филатов, Е.В. Бодянский, В.Е. Кучеренко и др. ; под общ. ред. Е.В. Бодянского. – Дніпропетровськ: Системні технології, 2008. – 403 с.
4. Касаткина, Н.В. Об одном подходе к интеллектуальному анализу реляционных баз данных / В.А. Филатов, Н.В. Касаткина // Вестник Херсонского национального технического университета № 1 (34) – 2009. – С. 157-161.
Ответы на вопросы [_Задать вопроос_]
Читайте также
Информационно-управляющие комплексы и системы
Теленик С.Ф., Ролік О.І., Букасов М.М., Андросов С.А. Генетичні алгоритми вирішення задач управління ресурсами і навантаженням центрів оброблення данихБогушевский В.С., Сухенко В.Ю., Сергеева Е.А., Жук С.В. Реализация модели управления конвертерной плавкой в системе принятия решений
Бень А.П., Терещенкова О.В. Применение комбинированных сетевых методов планирования в судоремонтной отрасли
Цмоць І. Г., Демида Б.А., Подольський М.Р. Методи проектування спеціалізованих комп’ютерних систем управління та обробки сигналів у реально-му час
Теленик С.Ф., РолікО.І., Букасов М.М., РимарР.В., Ролік К.О. Управління навантаженням і ресурсами центрів оброблення даних при виділених серверах
Селякова С. М. Структура інтелектуальної системи управління збиральною кампанією
Еременко А.П., Передерий В.И. Принятие решений в автоматизированных системах с учетом психофункциональных характеристик оператора на основе генетических алгоритмов
Львов М.С. Алгоритм перевірки правильності границь змінення змінних у послідовних програмах
Ляшенко Е.Н. Анализ пожарной опасности сосновых насаждений в зоне Нижне-днепровских песков – самой большой пустыни в Европе
Кучеров Д.П., Копылова З.Н. Принципы построения интеллектуального автору-левого
Ходаков В.Е., Жарикова М.В., Ляшенко Е.Н. Применение когнитивного подхода для решения задачи поддержки принятия управленческих решений при ликвидации лесных пожаров
Гончаренко А.В. Моделювання впливу ентропії суб’єктивних переваг на прийняття рішень стосовно ремонту суднової енергетичної установки
Фарионова Н.А. Системный подход построения алгоритмов и моделей систем поддержки принятия решений при возникновении нештатных ситуаций
Биленко М.С., Серов А.В., Рожков С.А., Буглов О.А. Многоканальная система контроля качества текстильных материалов
Мотылев K.И., Михайлов M.В., Паслен В.В. Обработка избыточной траекторной информации в измерительно-вычислительных системах
Гончаренко А.В. Вплив суб’єктивних переваг на показники роботи суднової енергетичної установки
Гульовата Х.Г., Цмоць І.Г., Пелешко Д.Д. Архітектура автоматизованої системи моніторингу і дослідження характеристик мінеральних вод
Соломаха А.В. Разработка метода упреждающей компенсации искажений статорного напряжения ад, вносимых выходными силовыми фильтрами
ПотапенкоЕ.М., Казурова А.Е. Высокоточное управление упругой электромеханической системой с нелинейным трением.
Кузьменко А.С., Коломіц Г.В., Сушенцев О.О. Результати розробки методу еквівалентування функціональних особливостей fuzzy-контролерів
Кравчук А. Ф., Ладанюк А.П., Прокопенко Ю.В. Алгоритм ситуационного управления процессом кристаллизации сахара в вакуум-аппарате периодического действия с механическим циркулятором
Абрамов Г.С., Иванов П.И., Купавский И.С., Павленко И.Г. Разработка навигационного комплекса для автоматического наведения на цель системы груз-управляемый парашют
Литвиненко В.И., Четырин С.П. Компенсация ошибок оператора в контуре управления следящей системы на основе синтезируемых вейвелет-сетей
Бардачев Ю.Н., Дидык А.А. Использование положений теории опасности в искусственных иммунных системах
Рожков С.О., Кузьміна Т.О., Валько П.М. Інформаційна база як основа для створення асортименту лляних виробів.
Ускач А.Ф., Становский А.Л., Носов П.С. Разработка модели автоматизированной системы управления учебным процессом
Мазурок Т.Л., Тодорцев Ю.К. Актуальные направления интеллектуализации системы управления процессом обучения.
Ускач А.Ф., Гогунский В.Д., Яковенко А.Е. Модели задачи распределения в теории расписания.
Сідлецький В.М., Ельперін І.В., Ладанюк А.П. Розробка алгоритмів підсистеми підтримки прийняття рішень для контролю якості роботи дифузійного відділення.
Пономаренко Л.А., Меликов А.З., Нагиев Ф.Н. Анализ системы обслуживания с различными уровнями пространственных и временных приоритетов.
Коршевнюк Л.О. Застосування комітетами експертів системи нечіткого логічного виводу із зваженою істинністю.. – С. 73 – 79.
Кирюшатова Т.Г., Григорова А.А Влияние направленности отдельных операторов и направленности всей группы на конечный результат выполнения поставленной задачи.
Петрушенко А.М., Хохлов В.А., Петрушенко І.А. Про підключення до мови САА/Д деяких засобів паралельного програмування пакету МРІСН.
Ходаков В.Е., Граб М.В., Ляшенко Е.Н. Структура и принципы функционирования системы поддержки принятия решений при ликвидации лесных пожаров на базе новых геоинформационных технологий.
Сидорук М.В., Сидорук В.В. Информационные системы управления корпорацией в решении задач разработки бюджета.
Нагорный Ю.И. Решение задачи автоматизированного расчета надежности иасуп с использованием модифицированного метода вероятностной логики
Козак Ю.А. Колчин Р.В. Модель информационного обмена в автоматизированной системе управления запасами материальных ресурсов в двухуровневой логистической системе
Гожий А.П., Коваленко И.И. Системные технологии генерации и анализа сценариев
Вайсман В.А., Гогунский В.Д., Руденко С.В. Формирование структур организационного управления проектами
Бараненко Р.В., Шаганян С.М., Дячук М.В. Аналіз алгоритмів взаємних виключень критичних інтервалів процесів у розподілених системах
Бабенко Н.И., Бабичев С.А. Яблуновская Ю.А. Автоматизированная информационная система управления учебным заведением
Яковенко А.Е. Проектирование автоматизированных систем принятия решений в условиях адаптивного обучения с учетом требований болонского процесса
Бараненко Р.В Лінеаризація шкали і збільшення діапазону вимірювання ємностей резонансних вимірювачів
Головащенко Н.В. Математичні характеристики шумоподібно кодованих сиг-налів.
Шерстюк В.Г. Формальная модель гибридной сценарно-прецедентной СППР.
Шекета В.І. Застосування процедури Append при аналізі абстрактних типів даних модифікаційних запитів.
Цмоць І.Г. Алгоритми та матричні НВІС-структури пристроїв ділення для комп'-ютерних систем реального часу.
Кухаренко С.В., Балтовский А.А. Решение задачи календарного планирования с использованием эвристических алгоритмов.
Бараненко Р.В., Козел В.Н., Дроздова Е.А., Плотников А.О. Оптимизация рабо-ты корпоративных компьютерных сетей.
Нестеренко С.А., Бадр Яароб, Шапорин Р.О. Метод расчета сетевых транзакций абонентов локальных компьютерных сетей.
Григорова А.А., Чёрный С. Г. Формирование современной информационно-аналитической системы для поддержки принятия решений.
Шаганян С.Н., Бараненко Р.В. Реализация взаимных исключений критических интервалов как одного из видов синхронизации доступа процессов к ресурсам в ЭВМ
Орлов В.В. Оценка мощности случайного сигнала на основе корреляционной пространственной обработки
Коджа Т.И., Гогунский В.Д. Эффективность применения методов нечеткой логики в тестировании.
Головащенко Н.В., Боярчук В.П. Аппаратурный состав для улучшения свойств трактов приёма – передачи информации в системах промышленной автоматики.