УДК 004.627
АЛГОРИТМ СЖАТИЯ ИНФОРМАЦИИ БЕЗ ПОТЕРЬ: МОДИФИЦИРОВАННЫЙ АЛГОРИТМ LZ77
Шеховцов А.В., Везумский А.К., Середа Е.С.
Введение. Количество информации необходимой человечеству в повседневной работе неуклонно растет. Объемы устройств, для хранения данных и пропускная способность линий связи также растут. Однако, количество информации растет намного быстрее. Данная проблема может быть решена 3 способами.
Первый – ограничение количества информации. К сожалению, он не всегда приемлем. Например, для изображений это означает уменьшение разрешения, что приведет к потере мелких деталей и может сделать изображения вообще бесполезными (например, для медицинских или космических изображений).
Второй – увеличение объема носителей информации и пропускной способности каналов связи. Это решение связано с материальными затратами, причем иногда весьма значительными.
Третий способ – использование сжатия информации. Этот способ позволяет в несколько раз сократить требования к объему устройства хранения данных и пропускной способности каналов связи без дополнительных издержек (за исключением издержек на реализацию алгоритмов сжатия). Условиями его применимости является избыточность информации и возможность установки специального программного обеспечения либо аппаратуры как вблизи источника, так и вблизи приемника информации. Как правило, оба эти условия удовлетворяются.
Первые теоретические разработки в области сжатия информации относятся к концу 40-х годов. В конце семидесятых появились работы Шеннона, Фано и Хафмана.
Необходимость сжатия информации в вычислительных сетях вытекает из того, что пропускная способность каналов связи более дорогостоящий ресурс, чем дисковое пространство, по этой причине сжатие данных до или во время их передачи очень актуально.
Здесь целью сжатия информации является экономия пропускной способности и в конечном итоге ее увеличение.
Все известные алгоритмы сжатия сводятся к шифрованию входной информации, а принимающая сторона выполняет дешифровку принятых данных.
Существуют методы, которые предполагают некоторые потери исходных данных, другие алгоритмы позволяют преобразовать информацию без потерь.
— Сжатие с потерями используется при передаче звуковой или графической информации, при этом учитывается несовершенство органов слуха и зрения, которые не замечают некоторого ухудшения качества, связанного с этими потерями.
— Сжатие информации без потерь осуществляется статистическим кодированием или на основе предварительно созданного словаря. Статистические алгоритмы (напр., схема кодирования Хафмана) присваивают каждому входному символу определенный код. При этом, наиболее часто используемому символу присваивается наиболее короткий код, а наиболее редкому - более длинный. Таблицы кодирования создаются заранее и имеют ограниченный размер. Этот алгоритм обеспечивает наибольшее быстродействие и наименьшие задержки. Для получения высоких коэффициентов сжатия статистический метод требует больших объемов памяти.
Постановка задачи. Известны основные типы избыточности, которые перечислил в своей работе Т. Велч [1]:
а) избыточность распределения событий (разные события имеют разные вероятности);
б) избыточность повторения событий (несколько одинаковых событий могут следовать друг за другом);
в) избыточность цепочек событий (цепочки событий могут повторяться);
г) позиционная избыточность – повышение вероятности появления определенных событий в некоторых позициях потока событий (например, в записях базы данных).
Приведенная классификация составлена в 1984 г. и практически не устарела, однако нуждается в некоторых дополнениях.
В представленной работе предлагается математическая модель, которая учитывает дополнительные условия избыточности и на основе существующего алгоритма сжатия текстовой информации без потерь разрабатывается новый алгоритм [1].
Дополнение 1. Классификация ориентирована в первую очередь на символьные источники информации. Нетекстовым источникам данных характерны свои виды избыточности. Например, графическим данным характерна пространственная избыточность, характеризующаяся высокой вероятностью близости не только значений соседних пикселей, но и их пространственных производных.
Дополнение 2. Избыточность цепочек событий может быть представлена альтернативным способом – как избыточность распределения событий после наступления некоторого количества непосредственно предшествующих событий. Практические реализации, основанные на таком подходе, обеспечивают заметно более высокую степень сжатия, чем просто устраняющие цепочечную избыточность.
Для начала рассмотрим метод группового кодирования: подавление нулей. Это один из старейших способов, который исключал избыточность типа б, упоминавшейся ранее. В данном методе текст сканируется на наличие повторяющихся символов. Если количество повторяющихся символов было более 3, то алгоритм заменял данную строку двухсимвольным кодом.
Пример: строка XYZbbbbbQRA заменялась на следующую строку — XYZSc5QRA.
Однако данный алгоритм имеет ряд недостатков. Один из наиболее важных недостатков — способность данного алгоритма устранять избыточность лишь одного типа символов. В факсимильной связи к примеру, это недостатком не является, что видно из рис. 1: присутствуют лишь чёрные и белые пиксели.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 1
Следующим шагом будет рассмотрение метода группового кодирования, исключающего недостатки предыдущего метода, в котором напомню, происходило подавление избыточности лишь одного типа символов. Данный алгоритм предлагает заменять повторения трёхсимвольным кодом. На рис. 2 иллюстрируется применение данного метода к символьным данным. Здесь используются следующие обозначения:
Sc — специальный символ, указывающий на то, что за ним следуют сжатые данные;
Х — любой повторяющийся символ;
Сс — счётчик символов, то есть количество повторений сжатого символа.
|
Sc |
X |
Cc |
Рис. 2 Формат сжатия при групповом кодировании
Примеры сжатия при групповом кодировании приведены в таблице 1.
Таблица 1
|
Исходная строка данных |
Кодированная строка данных |
|
$**********55.72 |
$Sc*1055.72 |
|
---------- |
Sc-10 |
|
SeredaaaaaaaaaaaEugen |
SeredaSca10Eugen |
Таким образом, данный метод позволяет сократить место, занимаемое любой последовательностью из четырёх и более одинаковых символов.
Рассмотрим алгоритм LZ77. Пусть имеется следующая бессмысленная фраза: the brown fox jumped over the brown foxy jumping frog. Длина этой фразы 53 байта, то есть 424 бита.
Алгоритм обрабатывает этот текст слева направо. Вначале каждый символ преобразуется в 9-битовый код, состоящий из двоичной единицы, за которой следует 8-битовое ASCII-представление символа. Во время обработки текста алгоритм ищет повторяющиеся последовательности.
Когда встречается повторяющаяся последовательность, алгоритм ищет конец такой последовательности, то есть каждый раз алгоритм отыскивает как можно больше символов. Первой такой последовательностью является the brown fox. Повторяющаяся последовательность заменяется указателем на первый экземпляр последовательности и длиной этой последовательности. В данном случае последовательность the brown fox встречается на 26 позиций раньше и имеет длину 13 символов. Для данного примера рассмотрим два варианта кодирования: 8-битовый указатель и 4-битовая длина или 12-битовый указатель и 6-битовая длина. При этом 2-битовый заголовок указывает, который вариант выбран: 00 означает первый вариант, а 01 — второй вариант. Таким образом, второй экземпляр последовательности the brown fox кодируется как <00b>,<26d><13d> или 00 00011010 1101.
Оставшиеся части сжатого сообщения представляют собой букву у, последовательность <00b><27d|><5d|>, заменяющую последовательность, состоящую из пробела, за которым следует строка jump, и последовательность символов ing frog.
На рис. 3 иллюстрируется преобразование алгоритма сжатия. Сжатое сообщение состоит из 35 9-битовых символов и двух кодов, то есть всего из 35 • 9 + + 2 • 14 = 343 бит. Таким образом, при 424 бит в несжатом сообщении коэффициент сжатия данного метода в этом примере составил 1,24.
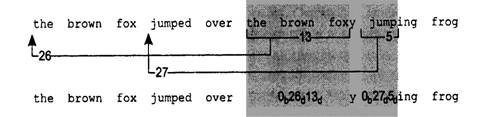
Рис. 3 Пример работы метода LZ77
Основная концепция. В процессе совершенствования существующих алгоритмов сжатия данных без потерь было обосновано выведено, что если отдельные кодируемые символы встречаются в исходном тексте с вероятностью Pi, то в лучшем случае мы можем использовать для каждого символа код длины Li, удовлетворяющей следующему неравенству:
|
|
|
Здесь Pi представляет собой вероятность, с которой i-ый символ встречается в исходных данных, а Li — длину двоичного кода, которым кодируется данный символ. Исходя из неравенства (1) можно показать, что:
|
|
|
Здесь Н(Х) представляет собой энтропию множества символов Х, а Е[L] является средней длиной кода для множества Х. В схеме сжатия без потерь Н(Х) всегда будет нижней границей объёма сжатых данных, так как Н(Х) определяет среднее количество информации, содержащейся в символьном наборе.
Согласно дополнению 2, приведённом в данной работе, эффективность алгоритма сжатия данных может быть повышена путём объединения символов и одновременного кодирования блоков по К символов каждый. В результате получаем следующее неравенство:
|
|
|
Таким образом, существует способ повышения эффективности алгоритма сжатия. Если нам нужно отправить сообщение длинной в N символов, мы можем использовать блок длинной N символов. Таким образом, мы обращаемся с каждым сообщением как с одним из MN возможных результатов, где М представляет собой количество атомарных символов, а N — длину сообщения.
Решение поставленной задачи. Как уже было оговорено ранее, эффективность алгоритма сжатия данных может быть повышена путём объединения символов и одновременного кодирования блоков по К символов каждый.
Пусть дан нам следующий текст: “ABCABEFJAB”, который состоит из 10 символов, а это в свою очередь 10 байт или 80 бит.
Алгоритм LZ77 предположим кодирует 1 способом: весь текст преобразуется в 9-битовый код, за которой следует 8 битовое ASCII-представление представление, а остальные кодированные блоки преобразует в 14 битовый код, состоящий из: 2 бит заголовка, 8 битового указателя и 4 битовой длины.
Итого, для данного текста общий размер будет: 6*9+2*14=82 бита, что на 2 бита больше незакодированного сообщения.
Заархивировав данное сообщение с помощью архиватора WinRar версии 7,0 beta 2, получил следующие результаты, смотри рис. 4. Как видно из рисунка, размер сжатого сообщения вышел 79 байт, что составляет 632 бита.
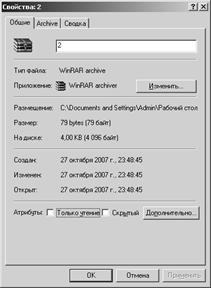
Рис. 4 Сжатие исходного текста с помощью WinRar
Теперь рассмотрим предложенный алгоритм, модифицированный метод сжатия LZ77. Здесь весь текст преобразуется в 9-битовый код, за которым следует 8 битовое ASCII-представление символа.
Закодированный текст будет выглядить так:
|
<0b> A |
<0b> B |
<0b> C |
1 <02d> |
<0b> E |
<0b> F |
<0b> J |
1 <02d> |
Как видно, перед каждым символом, добавлен бит: 0 — символ незакодирован, а 1 — символ закодирован. Обозначение <02d> означает число 02 в десятичном коде. После небольших манипуляций, получим 2 числа (0 и 2), где:
0 — позиция начла блока;
2 — количество символов в блоке.
Таким образом, мы получим 8 символов по 9 бит каждый, это 72 бита на весь текст. Исходя из полученного результата, степень сжатия для такого столь малого текста составляет 1,1111. Делая вывод, можно сказать, что полученный модифицированный алгоритм позволяет получить наилучшие показатели степени сжатия для малых текстов.
Однако, даже на этом этапе, можно обнаружить недостаток синтезированного алгоритма — максимальный показатель счётчика будет равен 9, и максимальное значение символов в блоке также будет равно 9.
Решить данную проблему можно следующим путём: преобразуем в 9-битовый код весь текст, за которым следует 8 битовое ASCII-представление символа. Теперь кодирование будет представляться следующим форматом: <x><y><z>, где:
<x> — это 1 бит указывающий кодирован символ или нет;
<y> — указывающий, какой вариант кодирования используется (I или II);
<z> — закодированный символ.
Отличия II вариант от I не особенно значительны, за исключением того, что все символы перекодируются в 9-битовый код, размер кода составит 12 бит, что позволяет нам использовать уже 99 позиций для смещения счётчика и 9 символов в блоке.
Для проверки работоспособности данного алгоритма и сравнения его работы, рассмотрим пример, когда передаётся сообщение по факсимильной связи. Пусть дана следующая последовательность, представленная в таблице 2.
Таблица 2.
Исходная последовательность
|
0000000000000000000000011110000001001000000111100000000010000000001000000111100000000000000000000000 |
Закодируем данную последовательность с помощью алгоритма LZ77, причём будем кодировать блоками по 3 символа и только нули. В результате мы получим: 24 блока по 3 символа, и 19 символов преобразованных в 9-битный код. В результате мы получим: 24*14+19*9=336+171=507 бит, степень сжатия при этом будет составлять 1.5779
Рассмотрим работу представленного алгоритма. Результатом кодирования в первом случае будет: (24+19)*9=387 бит, а степень сжатия будет 2,0671. Во втором варианте кодирования результат будет следующий: (24*12)+(19*9)=288+171=459 бита, а степень сжатия в данном случае будет равной 1,7429.
Этот же тип данных, сжатый с помощью оговоренного ранее программного обеспечения WinRAR в результате получил размер, равный 102 байтам, что в свою очредь составляет 816 бит, что намного больше размера исходных данных.
Заключение. Необходимо учитывать, что при устранении одних видов избыточности, другие виды избыточности, присущие тому же потоку событий, могут исчезать (например, после устранения в потоке символов избыточности типа “а” устранить другие типы избыточности не представляется возможным) или сохраняться (например, при устранении избыточности типа “б” может сохраняться избыточность типа “а”, хотя ее характеристики несколько меняются). Кроме того, в выходном потоке при устранении определенных видов избыточности могут появляться новые виды избыточности.
Учитывая новые условия избыточности, был предложен модифицированный алгоритм сжатия данных без потерь на основе уже существующего алгоритма LZ77. Экспериментальные исследования наглядно продемонстрировали эффективность модифицированного алгоритма.
Использование данного алгоритма позволит достичь более высоких результатов сжатия информации передаваемой в факсимильной связи, а тем самым, сократить время для передачи сообщения и расходы при междугородней и международной связи.
In the presented work it is offered to enter additional conditions of redundancy. One of additional conditions consists that: redundancy of chains of events can be presented by alternative way - as redundancy events after approach of quantity previous events. The practical realizations based on such approach, provide noticeably higher degree of compression, than simply eliminating chained redundancy. On the basis of existing algorithm of compression of the text information the new algorithm which has shown higher degrees of compression unlike other considered algorithms lost-free is developed.
1. Современные компьютерные сети. 2-3 изд. / В. Столингс.—СПб.:Питер, 2003.—783с.
2. Теория вероятностей и математическая статистика / В.Е. Гмурман— М.: Высш. шк., 2000.—250с.
Ответы на вопросы [_Задать вопроос_]
Читайте также
Информационно-измерительные системы
Ковальов О.І. Вимірювання у процесно-орієнтованих стандартахПолякова М.В., Ищенко А.В., Худайбердин Э.И. Порогово-пространственная сегментация цветных текстурированных изображений на основе метода JSEG
Дзюбаненко А. В. Организация компьютерных систем для анализа изображений
Гордеев Б.Н., Зивенко А.В., Наконечный А.Г. Формирование зондирующих импульсов для полиметрических измерительных систем
Богданов А.В., Бень А.П., Хойна С.И. Релаксация обратного тока диодов Шоттки после их магнитно-импульсной обработки (МИО)
Тверезовский В.С., Бараненко Р.В. Проектирование измерителя добротности варикапов
Тверезовский В.С., Бараненко Р.В. Оптимизированная модель измерителя доб-ротности варикапов
Руднєва М.С., Кочеткова О.В., Задорожній Р.О. Принципи побудови оптимальної структури інформаційно-вимірювальної системи геометричних розмірів об’єктів в діапазоні від 1 нм до 1000 нм
Биленко М.С., Рожков С.А., Единович М.Б. Идентификация деформаций пе-риодических структур с использованием систем технического зрения
Рашкевич Ю.М., Ковальчук А.М., Пелешко Д.Д. Афінні перетворення в модифікаціях алгоритму RSA шифрування зображень
Дидык А.А., Фефелов А.А, Литвиненко В.И., Шкурдода С.В., Синяков Ф. В. Классификация масс-спектров с помощью кооперативного иммунного алгоритма
Клименко А.K. Обратная модель для решения задач в системах с многосвязными динамическими объектами
Завгородній А.Б. Порівняльне дослідження твердотільних і рідиннофазних об'єктів методом газорозрядної візуалізації
Голощапов С.С., Петровский А.В., Рожко Ж.А., Боярчук А.И. Измерение доб-ротности колебательного контура на основе метода биения частот
Кириллов О.Л., Якимчук Г.С. Диагностирование критерия безопасности при заполнении замкнутых объемов СПЖ косвенным методом
Долина В.Г. Проблеми підвищення точності рефрактометра на основі прозорих порожнистих циліндрів.
Самков О.В., Захарченко Ю.А. Застосування алгоритму клонального відбору для побудови планів модернізації авіаційної техніки
Попов Д.В. Метод формування регламентів технічного обслуговування повітряних суден
Казак В.М., Чорний Г.П., Чорний Т.Г. Оцінювання готовності технічних об’єктів з урахуванням достовірності їх контролю
Тверезовский В.С., Бараненко Р.В. Технические аспекты проектирования цифрового измерителя добротности варикапов
Тверезовский В.С., Бараненко Р.В. Технические аспекты проектирования устройства для разбраковки варикапов по емкостным параметрaм и добротности
Сосюк А.В. Інтелектуальний автоматизований контроль знань в системах дистанційного навчання
Соколов А.Є. Деякі аспекти систезу комп’ютеризованої адаптивної системи навчання
Полякова М.В., Волкова Н.П., Іванова О.В. Сегментація зображень стохастичних текстур амплітудно-детекторним методом у просторі вейвлет-перетворення
Луцкий М.Г., Пономаренко А.В., Филоненко С.Ф. Обработка сигналов акустической эмиссии при определении положения сквозных дефектов
Литвиненко В.И., Дидык А.А., Захарченко Ю.А. Компьютерная система для решения задач классификации на основе модифицированных иммунных алгоритмов
Лубяный В.З., Голощапов С.С. Прямоотсчетные измерители расхождений емкостей
Беляев А.В. Построение навигации для иерархических структур в WEB-системах и системах управления WEB-сайтом
Терновая Т.И., Сумская О.П., Слободянюк И.И., Булка Т.И. Контроль качества тканей специального назначения с помощью автоматических систем.
Шеховцов А.В. Інформаційний аспект: розпізнавання образів індивідуума.
Полякова М.В. Определение границ сегмента упорядоченной текстуры на изображении с однородным фоном с помощью многоканального обнаружения пачки импульсов.
Литвиненко В.И. Прогнозирования нестационарных временных рядов с помощью синтезируемых нечетких нейронных сетей
Ковриго Ю.М., Мисак В.Ф., Мовчан А.П., Любицький С.В. Автоматизована система діагностики генераторів електростанцій
Браїловський В.В., Іванчук М.М., Ватаманюк П.П., Танасюк В.С. Керований детектор імпульсного ЯКР спектрометра
Забытовская О.И. Построение функции полезности по экспериментальным данным.
Шиманські З. Апаратні засоби сегментації мовного сигналу
Хобин В.А., Титлова О.А. К вопросу измерения парожидкостного фронта в дефлегматоре абсорбционно-диффузионной холодильной машины (АДХМ)
Фефелов А. А. Использование байесовских сетей для решения задачи поиска места и типа отказа сложной технической системы
Слань Ю. М., Трегуб В. Г. Оперативна нейромережна ідентифікація складних об’єктів керування
Ролик А.И. Модель управления перераспределением ресурсов информационно-телекоммуникационной системы при изменении значимости бизнес-процессов
Кириллов О.Л., Якимчук Г.С., Якимчук С.Г. Изучение электрического поля с помощью датчика измерителя электростатического потенциала на модели замкнутого металлического объема
Грицик В.В. Застосування штучних нейронних мереж при проектуванні комп’ютерного зору.
Гасанов А.С. Информационные технологии построения систем прогнозирования отказов
Ходаков В.Е., Жарикова М.В., Ляшенко Е.Н. Методы и алгоритмы визуализации пространственных данных на примере моделирования распространения лесных пожаров.
Полякова М.В., Крылов В.Н. Обобщённые масштабные функции с компактным носителем в задаче сегментации изображений упорядоченных текстур. – C. 75 – 84.
Полторак В.П., Дорогой Я.Ю. Система распознавания образов на базе нечеткого нейронного классификатора.
Литвиненко В.И. Синтез радиально-базисных сетей для решения задачи дистанционного определения концентрации хлорофилла.
Бражник Д.А. Управление совмещением изображения объекта в сцене и эталонного изображения.
Бабак В.П., Пономаренко А.В. Локализация места положения сквозных дефектов по сигналам акустической эмиссии.
Мороз В. В. R-D проблема и эффективность систем сжатия изображений.
Крылов В.Н., Полякова М.В., Волкова Н.П. Контурная сегментация в пространстве гиперболического вейвлет-преобразования с использованием математической морфологии.
Квасников В.П., Баранов А.Г. Анализ влияния дестабилизирующих факторов на работу биканальной координатно-измерительной машины.
Казак В.М., Гальченко С.М., Завгородній С.О. Аналіз можливості застосування імовірнісних методів розпізнавання для виявлення пошкоджень зовнішнього обводу літака.
Тищенко И.А., Лубяный В.З. Управление коммутационными процессами в интегрированных сетях связи.
Корниенко-Мифтахова И.К.,Филоненко С.Ф. Информационно-измерительная система для анализа характеристик динамического поведения конструкций.
Тверезовский В.С., Бараненко Р.В. Модель измерителя емкости с линейной шкалой измерений.
Полякова М.В., Крылов В.Н. Мультифрактальный метод автоматизированного распознавания помех на изображении.
Рожков С.О., Федотова О.М. Алгоритм розпізнавання дефектів тканин для автоматичної системи контролю якості.
Бражник Д.А. Использование проективного преобразования для автоматизации обнаружения объектов.
Ходаков В.Є., Шеховцов А.В., Бараненко Р.В. Математичні аспекти створення автоматизованої системи „Реєстр виборців України”