УДК 004.75
УПРАВЛІННЯ НАВАНТАЖЕННЯМ І РЕСУРСАМИ ЦЕНТРІВ ОБРОБЛЕННЯ ДАНИХ ПРИ ВИДІЛЕНИХ СЕРВЕРАХ
Теленик С.Ф., РолікО.І., Букасов М.М., РимарР.В., Ролік К.О.
Вступ. Розвиток інформаційних технологій (ІТ) призвів до формування і втілення у кінці ХХ – на початку ХХІ століть концепції інформаційно-телекомунікаційних систем (ІТС). В цих великих розподілених системах на якісно новому рівні реалізуються ідеї, пов’язані з удосконаленням інформаційно-обчислювальних процесів. Так, у 70-х – 80-х роках минулого століття перспективною видавалася ідея концентрації інформаційно-обчислювальних ресурсів у обчислювальних центрах колективного використання (ОЦКВ). Міністерства і відомства з їх розподіленою системою підпорядкованих підприємств, організацій, установ і окремих підрозділів вбачали у ОЦКВ багатообіцяючу форму забезпечення підпорядкованих органів управління обчислювальною технікою і збільшення ефективності її використання. Низка причин стали на заваді втілення цієї ідеї. Сьогодні ОЦКВ повернулися у вигляді центрів оброблення даних (ЦОД) – комплексних організаційно-технічних рішень, призначених для створення високопродуктивних, відмовостійких ІТ-інфраструктур. Орієнтовані на вирішення проблем бізнесу шляхом надання послуг у вигляді інформаційних сервісів ЦОД забезпечують ефективне консолідоване зберігання і оброблення даних користувачів, надання їм прикладних сервісів, а також підтримку функціонування корпоративних застосувань.
Концепція ЦОД втілена багатьма великими корпораціями переважно для забезпечення доступу великої кількості користувачів до певних ресурсів (сервісів, застосувань, обчислювальних потужностей, даних тощо). Виявилося, що ефективна організація ЦОД пов’язана з необхідністю розв’язання низки проблем, насамперед створення умов для функціонування інформаційно-обчислювальних потужностей ЦОД, управління ресурсами, забезпечення надійності та безпеки. Схожі проблеми постають перед будь-якою компанією, яка вкладає кошти у створення системи ЦОД для обслуговування користувачів інших компаній, тобто набуде статусу хостингової компанії.
У статті розглядається підхід до управління розподілом ресурсів ЦОД, призначений забезпечити ефективне їх використання у процесі функціонування ЦОД за схемою виділених серверів. Наводяться моделі і алгоритми розподілу ресурсів, структура відповідних інструментальних засобів.
1 Проблеми організації роботи ЦОД. Проблема створення і забезпечення ефективного функціонування ЦОД постає перед корпораціями з розвиненою розподіленою ІТ-інфраструктурою, насамперед хостинговими компаніями. Вкладаючи кошти, компанії сподіваються на прибуток. У будь-якому випадку вони очікують зменшення витрат на експлуатацію ЦОД, зниження вартості обслуговування користувачів, що дозволить, зрештою, закласти основу для ефективної діяльності, як самої компанії, так і клієнтів.
Клієнти своє бачення роботи ІТ-інфраструктури погоджують із хостинговою компанією на рівні вимог, до яких звичайно належать: вартість послуг; доступність і керованість ІТ-інфраструктури; цілісність даних; безпека; надійність; масштабованість.
Досягнення рівня вимог користувачів найменшими коштами становить сутність проблеми створення і забезпечення функціонування ЦОД. Зазвичай цю комплексну проблему розбивають на ряд проблем менших розмірів, але від того не набагато простіших. Однією з них є проблема управління ресурсами і навантаженням ЦОД.
Потрібні гнучкі рішення, які ґрунтуються на оцінюванні і прогнозуванні стану ресурсів і обсягів навантаження і полягають у правильному балансуванні навантаження і ефективному розподілі ресурсів. Для систематичного прийняття правильних рішень необхідні інструментарій та комплекс методик для вирішення задач підтримки ІТ-інфраструктури. Їх створення становить важливу науково-практичну проблему, розв’язання якої вимагає глибокого розуміння процесів, які відбуваються в хостингових компаніях, функціонування ІТ-інфраструктури, чіткої постановки конкретних задач дослідження, розроблення математичних моделей і відповідних методів вирішення задач та, насамкінець, реалізації згаданих вище інструментарію та методик.
Комплекс задач дослідження та їх постановки залежать від багатьох чинників, які тією чи іншою мірою впливають на згадані вище процеси. Першим таким чинником є модель хостингу. В цій статті розглядається модель виділених серверів, за якої клієнти не змагаються за ресурси, а мають можливість використовувати резервовані для них фізичні сервери, вважаючи, що це захистить їх від перевантаження серверів, поганої продуктивності і недосконалих програм їх сусідів по хостингу.
Другим важливим чинником є прийнята архітектура побудови програмних систем. У статті пропонуються моделі для традиційної і сервіс-орієнтованої архітектури (СОА). Перша з них ґрунтується на абстракціях застосувань та елементів їх побудови. Переважно використовується трирівнева архітектура із сервером БД, сервером застосувань і клієнтом. У СOA ідеологія побудови виходить із абстракції сервісів. Мета розроблення системи полягає у створенні комплексу прийнятного рівня абстракцій сервісів, які використовуються багатьма застосуваннями, а не жорстко прив’язуються до одного з них.
Для масштабування систем, гнучкого розподілу їх ресурсів між клієнтами і балансування навантаження, хостингові організації використовують клієнт-серверні і Web-технології, технології віртуалізації і кластеризації.
Клієнт-серверні технології побудови і організації доступу до прикладного програмного забезпечення (ПЗ) призначені для ефективної реалізації необхідної функціональності програмних систем, створення умов для ефективної підтримки діяльності бізнес-персоналу компанії, пов’язаної зі здійсненням системи бізнес-процесів компанії. До цих технологій багато в чому близькі Web-технології побудови і організації доступу до прикладного ПЗ, оскільки їх поява була реакцією на ті ж проблеми. Процеси оброблення інформації бізнес-користувачів в них також розподіляють між трьома типами взаємодіючих програмних компонентів – сервером БД, клієнтом і Web-сервером застосувань. Іноді для організації роботи з користувачами виділяється окремий Web-сервер, який управляє запитами до серверів застосувань.
Застосування клієнт-серверних і Web-технологій забезпечує зниження рівня вимог до робочих станцій, розподіл процесорного навантаження і оптимізацію серверів, масштабування систем і підвищення їх швидкодії, зменшення непродуктивних витрат.
Технології віртуалізації надають користувачу можливість абстрагуватися від особливостей окремих груп ресурсів, об’єднати їх у апаратно-програмні комплекси потрібної конфігурації і спростити управління ними. Віртуалізація платформ полягає у створенні віртуальних машин (ВМ) – програмних абстракцій, що запускаються на платформі реальних апаратно-програмних (хостових) систем. Віртуалізація ресурсів узагальнює підходи до створення ВМ і переносить їх на усі види ресурсів – обладнання ЦОД, просторів імен, мереж і т.п.
Технологія кластерного хостингу дозволяє користувачам керувати безпекою, ресурсами і балансуванням навантаження. До того ж, кластерні платформи хостингу управляться даними, що дозволяє багато операцій виконувати без втручання людини. Після замовлення акаунта користувач може використовувати ресурси хостингу, замовляючи їх в межах фізичних обмежень платформи. Користувачі можуть використовувати ресурси декількох серверів, їх застосування розподіляються в реальному часі за рахунок віртуалізації ресурсів, які надаються фізичними серверами. Зміни в акаунті користувача поширюються без затримки на кожний сервер кластера. Комбіноване управління (динамічне балансування запитів між декількома застосуваннями і додавання серверів у кластер) убезпечує існуючих користувачів від падіння продуктивності і дозволяє успішно справлятися з великими обсягами трафіку.
Але досягнення переваг клієнт-серверних і Web-технологій, кластеризації і віртуалізації вимагає додаткових зусиль, оскільки процеси прийняття рішень стають складнішими і вимагають розвиненого інструментарію їх підтримки. Необхідно визначити склад кластерів, параметри ВМ і ефективно управляти їх навантаженням і ресурсами. З’являється необхідність розроблення моделей, алгоритмів і засобів моніторингу, аналізу, планування і управління інформаційно-обчислювальними процесами ЦОД з урахуванням специфіки архітектурних рішень, особливостей кластеризації і віртуалізації та реалізації їх у системі управління ІТ-інфраструктурою (СУІ) [1-2].
2 Аналіз існуючих рішень. Хостингові компанії управляють ресурсами і навантаженням за допомогою спеціалізованих програмно-апаратних рішень. Ринок СУІ насичений продуктами, створеними на основі IT Infrastructure Library (IТIL) і концепції IT Service Management (IТSM). Провідні позиції посідають компанії Microsoft з MS Data Center, IBM з лінійкою продуктів Tivolі, HP з OpenView Service Desk і Automation Manager.
Ефективність СУІ суттєво залежить від моделей і методів розв’язання наукових проблем, пов’язаних із розподілом ресурсів, управлінням ресурсами і навантаженням, балансуванням тощо. На сьогодні проблема розподілу ресурсів і управлінням навантаженням розв’язана не лише в межах єдиної апаратної системи, а й у мережах, насамперед для віртуального хостингу [3-8]. Запропоновано низку підходів для планування і управління ресурсами і навантаженням ІТС [9-12]. Але розподіл і управління серверами і групами серверів при використанні хостинговою компанією моделі виділених серверів вимагає додаткових досліджень. Крім того, розроблення моделей і методів ефективного управління навантаженням і ресурсами ЦОД при хостингу на основі виділених серверів складе важливу частину комплексного рішення для розподілу і управління ресурсами ЦОД, яке можна було б застосовувати в будь-якій ситуації, налаштовуючи його на особливості середовища застосування.
3 Постановка проблеми розподілу і управління ресурсами при виділених серверах. Модель хостингу з виділеними серверами підтримується клієнт-серверними і сервіс-орієнтованими технологіями. Фізичні сервери дозволяється об’єднувати в кластери для задоволення вимог клієнтів. Серверний парк ЦОД обслуговує визначену множину користувачів, надаючи їм доступ до множини відповідних застосувань клієнтів хостингової компанії. Сервери характеризуються набором технічних параметрів, а клієнти – набором вимог, залежних від множини користувачів і застосувань клієнтів. Вимоги застосувань такі, що декілька серверів забезпечують екземпляри одного застосування.
Необхідно розробити математичні моделі і відповідні методи розподілу фізичних серверів між клієнтами за доцільними критеріями ефективності за умови виконання ресурсних, технологічних та інших актуальних обмежень.
4 Опис функціонування ЦОД на основі виділених серверів. Розглянемо функціонування ЦОД, коли клієнти вибрали модель хостингу на основі виділених серверів. Хостингова компанія і організації-клієнти мають можливість вибирати технології побудови застосувань, кластеризації і віртуалізації. Нижче описано три варіанти системи, яка надає хостингові послуги на основі моделі виділених серверів.
4.1 Виділені сервери і СОА. Кожний клієнт одержує у своє використання один фізичний сервер або групу фізичних серверів. В останньому випадку використовуються технології кластеризації для об’єднання фізичних серверів у кластер. На серверах і кластерах можуть використовуватися технології віртуалізації. Кожний із клієнтів створює свої програмні системи на основі СОА. Веб-застосування обробляють веб-запити користувачів клієнта і веб-сервери генерують деякий статичний або динамічний вміст.
Адміністратори встановлюють Веб-сервер, сервер БД і застосування клієнта на фізичних серверах і кластерах клієнта, формуючи обчислювальне середовище для користувачів цього клієнта. Схема, наведена на рис. 1, демонструє організацію доступу до ресурсів при виділених серверах.
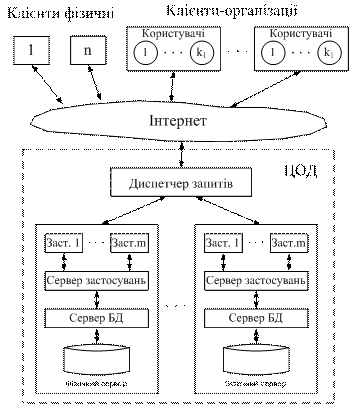
Рис. 1 Схема доступу до ресурсів при виділених серверах
На схемі зображено два фізичних сервери, на кожному з яких розгорнуті сервер БД, web-сервер застосувань і декілька застосувань окремого клієнта. Один ЦОД може обслуговувати багато різноманітних web-серверів застосувань, розгорнутих на фізичних серверах або в кластерах в кількості від n×10 до n×100. Оскільки окремі фізичні сервери ЦОД можуть не мати достатніх обчислювальних потужностей, оперативної пам'яті або інших ресурсів, адміністратори ЦОД створюють для клієнтів з високим рівнем вимог до ресурсів кластери на основі груп фізичних серверів.
Програмні середовища web-серверів застосувань використовують програмні реалізації диспетчерів запитів, щоб доставити web-серверні запити застосуванням. При віртуалізації можуть застосовуватися технології розподілу ресурсів ВМ і навантаження на основі спеціальних правил для вибору ВМ і застосувань. В СУІ також реалізується відстеження всього шляху запитів і запобігання ситуаціям, коли запит втрачається через зависле застосування або інші технічні проблеми.
4.2 Виділені сервери і традиційна трирівнева архітектура. Кожному клієнту виділяється окремий фізичний сервер або окрема їх група, причому в останньому випадку можуть використовуватися технології кластеризації. Кожний із клієнтів створює свої програмні системи на основі традиційних клієнт-серверних технологій. Сервери застосувань аналізують запити користувачів, перевіряють певні параметри і направляють запити відповідним застосуванням. Застосування обробляють запити користувачів клієнта і результати через сервер застосувань повертаються користувачам. Сервери застосувань, за необхідності, звертаються за даними до серверів БД.
Адміністратори встановлюють сервер застосувань, сервер БД і застосування клієнта на фізичному сервері, формуючи обчислювальне середовище для користувачів цього клієнта. У випадку групи серверів таке середовище формується на кластері. Як для окремих серверів, так і для кластерів можуть застосовуватися технології віртуалізації.
Програмні середовища серверів застосувань також використовують програмні реалізації диспетчерів запитів, щоб доставити запити застосуванням, а відповіді користувачам. Вони прив’язують запити до сервера застосувань і передають їх конкретним застосуванням для оброблення. Якщо задіяні технології віртуалізації, то застосовуються технології розподілу ресурсів ВМ і навантаження на основі спеціальних правил для вибору ВМ і застосувань.
4.3 Гібридна архітектура. Принципово можлива реалізація моделі, коли частина клієнтів будують свої програмні системи на основі СОА і використовують канали Інтернет для забезпечення доступу користувачів до своїх Web-застосувань, а інші клієнти використовують канали зв’язку із хостинговою компанією чи виділені канали і традиційні клієнт-серверні технології для забезпечення доступу своїх користувачів до застосувань.
5. Опис системи управління ІТ-інфраструктурою. На сьогодні для будь-якого з наведених варіантів побудови системи надання послуг з виділеними серверами проблема розподілу фізичних серверів і груп серверів між клієнтами залишається не розв’язаною. Коли ЦОД обслуговує значну кількість клієнтів, до великої кількості застосувань яких звертається багато користувачів, причому кожний клієнт і його застосування мають свої системні вимоги, а потужний серверний парк характеризується суттєвим різноманіттям параметрів, проблема найкращого закріплення серверів за клієнтами стає далеко не тривіальною.
Схема СУІ зображена на рис. 2. Власне ця система є розподіленою і на схемі зображено лише компонент, який відповідає за збір інформації щодо стану і завантаженості серверів і застосувань, аналіз зібраної інформації, розподіл серверів між клієнтами. На схемі не зображено той компонент системи, який розміщується на кожному сервері і реалізує функції моніторингу, аналізу і управління застосуваннями. Відповідно не знайшов відображення компонент управління кластером.
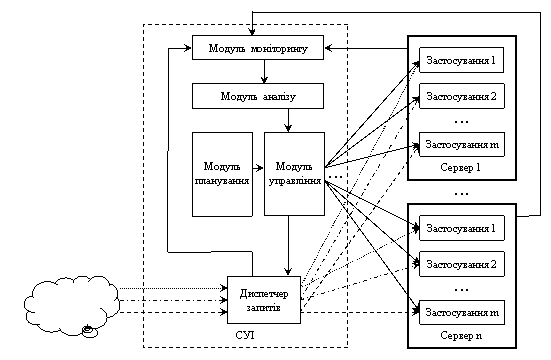
Рис. 2 Структурна схема управління навантаженням і ресурсами
Функціональне призначення елементів системи:
- модуль моніторингу відповідає за збір інформації компонентів системи і дотримання параметрів функціонування;
- модуль аналізу здійснює аналіз інформації стану і визначає ступінь відповідності функціонування системи визначеним критеріям її функціонування;
- диспетчер запитів здійснює маршрутизацію запитів відповідно до розподілу серверів між клієнтами;
- модуль планування визначає нове закріплення фізичних серверів (груп серверів) між клієнтами;
- модуль управління здійснює розгортання Web-серверів і застосувань відповідно до нового закріплення фізичних серверів між клієнтами, їх налаштування і формування правил для диспетчера.
Головний елементом моделі є модуль планування, який розраховує нове закріплення фізичних серверів за клієнтами, залежно від вимог клієнтів, потреб їх застосувань до ресурсів. У кожному новому циклі роботи системи модуль планування розраховує нову матрицю закріплення з метою задовольнити вимоги всіх клієнтів та їх застосувань в ресурсах, не перевищуючи місткості вузлів. На додаток до цього, модуль планування працює, враховуючи такі чинники:
- потенційну часо- і ресурсозатратність процесів згортання і розгортання застосувань на виділених для клієнта серверах;
- якщо існує багато матриць закріплення, які мінімізують витрати на підтримку виділених серверів і забезпечують виконання ресурсних обмежень, то найкращим з закріплень буде те, яке забезпечує рівномірне використання ресурсів;
- технологічні обмеження, які унеможливлюють використання деяких серверів для деяких клієнтів, наприклад налаштування мережі, присутність програмних бібліотек і т.п.
Вимоги клієнтів і застосувань традиційно поділяються на залежні від навантаження і незалежні від навантаження. Незалежні від навантаження вимоги описують ресурси, які необхідні для розгортання застосування на сервері застосувань. Приклади таких ресурсів – це оперативна пам'ять, і пам'ять на жорстких дисках. Залежні від навантаження вимоги відповідають ресурсам, використання яких залежить від загального навантаження на систему. Прикладами таких ресурсів можуть бути процесор, канали зв’язку. Доцільно також урахувати і потім контролювати якісні вимоги клієнтів, зазначені у SLA.
У статті не розглядаються планування і управління операціями згортання і розгортання екземплярів застосувань, оскільки це притаманне лише віртуальному хостингу. Можна використовувати операції запуску і зупинки ВМ, якщо використовуються технології віртуалізації, але це тема окремої статті.
Потрібна модель закріплення клієнтів за фізичними серверами і групами фізичних серверів з урахуванням наведених вище особливостей ІТ-інфраструктури.
6. Математична модель. Для того щоб сформулювати задачу оптимального розподілу ресурсів, введемо наступні позначення для найзагальніших понять, показників та параметрів, за допомогою яких можна описати систему, яка надає послуги користувачам, розподіляючи запити екземплярам застосувань на існуючих серверах:
1) N={N1,…,Nn} – множина фізичних серверів, кількість яких дорівнює n;
2) K={K1,…,Kn} – множина клієнтів, кількість яких дорівнює m;
3) кожний сервер Nі, і=1,…,n, має п’ять параметрів, які разом характеризують його потужність: Ωі – процесорна місткість сервера Nі; Gі – місткість оперативної пам’яті сервера Nі; Fі – місткість жорстких дисків сервера Nі; Lі – місткість каналів сервера Nі; Dі – надійність сервера Nі;
4) кожний клієнт Kj, j=1,…,m, має вимоги до: wj – процесорної місткості серверів, на яких розташовані застосування, які обслуговують користувачів клієнта Kj; gj – до оперативної пам'яті серверів, на яких розташовані застосування, які обслуговують користувачів клієнта Kj; jj – до пам'яті жорстких дисків серверів, на яких розташовані застосування, які обслуговують користувачів клієнта Kj; lj – до місткості каналів серверів, на яких розташовані застосування, які обслуговують користувачів клієнта Kj; dj – до надійності апаратно-програмного комплексу, який обслуговує користувачів клієнта Kj;
5) Матриця R=|Rji|m×n, де
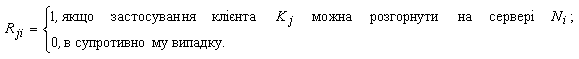
Особливість характеристик серверів і вимог застосувань полягає в тому, що вони поділяються на два класи: залежні від навантаження (Ωі, wj, Lі, lj) і не залежні від навантаження (Gі, gj, Fі, jj, Dі, dj). Вимоги до залежних від навантаження параметрів серверів визначаються сумарними вимогами користувачів клієнта, а вимоги до незалежних від завантаження параметрів серверів – сумарними вимогами усіх застосувань клієнта.
З опису системи, яка моделюється, легко зрозуміти, що величину wj можуть забезпечити декілька серверів своєю сумарною процесорною місткістю. Тоді на кожному сервері розміщується екземпляр застосування. Але величини gj визначаються потребами застосувань клієнта і якщо пам’ять сервера менше вимог застосування, то це застосування на сервері не може бути розміщеним. Тобто оперативну пам’ять застосуванню клієнта може надати лише той сервер, на якому воно розміщується. Якщо застосування розміщується на декількох серверах, то кожний з них має виділити для нього оперативної пам’яті відповідно до вимог застосування. Це ж стосується і пам’яті жорстких дисків серверів. Тому вимоги кожного клієнта Kj, j=1,…,m, до оперативної пам'яті складаються з сумарних вимог gSj до оперативної пам'яті усіх застосувань клієнта Kj та вимог gmaxj найвимогливішого щодо оперативної пам'яті застосування клієнта Kj. Аналогічно вимоги кожного клієнта Kj, j=1,…,m, до пам’яті жорстких дисків складаються з сумарних вимог jSj до пам’яті жорстких дисків усіх застосувань клієнта Kj та вимог jmaxj найвимогливішого щодо пам’яті жорстких дисків застосування клієнта Kj.
Вводимо змінну:
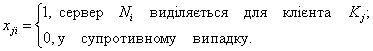
Виходячи з особливостей структури СУІ, задачу розбиваємо на дві:
1) планування розміщення застосувань на серверах (на період, за певних ситуацій);
2) диспетчерування навантаження протягом планового періоду.
Перша з цих задач, в свою чергу, розбивається на підзадачу закріплення серверів за клієнтами і підзадачу розміщення екземплярів застосувань. Друга підзадача може зводитися до тривіального розміщення усіх прикладів застосувань на сервері, причому у випадку віртуалізації вона становить цікаву задачу розміщення застосувань на віртуальних машинах. Але це тема окремої статті. Якщо клієнт для доступу своїх користувачів до застосувань, розташованих на групі серверів використовує віртуальний хостинг, то можна використовувати моделі та підходи, запропоновані авторами у праці [8].
Диспетчерування при виділених серверах також може звестися до жорстких схем направлення запитів до виділених серверів, але при віртуалізації і віртуальному хостингу на групі виділених для клієнта серверів моделі можуть бути значно цікавішими. Розпочнемо із математичних моделей закріплення серверів за клієнтами.
6.1 Моделі планування розподілу ресурсів. Задачу закріплення серверів за клієнтами доцільно розглядати як задачу визначення матриці X=||xji||, яка визначає прив’язку клієнтів до серверів.
Оптимальне розміщення повинне враховувати такі обмеження:
1) сумарні вимоги, незалежні від навантаження, визначених для сервера екземплярів застосувань не перевищують незалежні від навантаження параметри сервера;
2) вимоги застосувань, залежні від завантаження, визначаються на основі потенціалу усіх користувачів і повинні бути забезпечені сумарними можливостям залежних від завантаження параметрів тих серверів, на яких розміщуються екземпляри цього застосування;
3) обмеження, визначені матрицею R.
В якості критеріїв можна використовувати:
1) максимальну сумарну важливість застосувань, які отримали ресурси;
2) рівномірне завантаження серверів;
3) максимальні скорочення експлуатаційних витрат за рахунок вивільнення серверів;
4) мінімальна сумарна вартість реалізації операцій переходу від попереднього розміщення до нового.
Очевидно, що мова має йти про одну багатокритеріальну задачу. Але особливості критеріїв такі, що доцільніше розглядати декілька моделей із суттєвими відмінностями у забезпеченості серверами.
6.1.1 Моделі планування при обмежених ресурсах. Для цього можна використовувати моделі, запропоновані авторами для розподілу обмежених ресурсів ІТС у працях [9-11].
6.1.2 Моделі планування при надлишку ресурсів. В залежності від стратегії хостингової організації можна вибрати одну із моделей, які відрізняються критеріями.
Задача 1. Якщо кластеризація серверів не підтримується і для хостингової компанії важлива економія ресурсів, то виникає задача мінімізації витрат на підтримку тієї частини серверів, яка забезпечуватиме підтримку запитів користувачів клієнта. Тобто вибирається така мінімальна за витратами на їх підтримку підмножина серверів, які зможуть забезпечити виконання вимог застосувань.
Вважаємо, що дискова пам’ять організована у сховищах SAN-системи, доступ до яких мають усі екземпляри застосувань, на яких би серверах вони б не розміщувалися.
Позначимо через sі експлуатаційні витрати на підтримку сервера Ni (електроенергія, роботи, комплектуючі тощо). Тоді критерій цієї задачі набуде такого вигляду:
|
|
(1) |
Мінімальне значення треба вибирати із рішень, які відповідають структурі булевих значень матриці R=|Rji|m×n та таким обмеженням:
|
|
(2) |
Обмеження (2) вимагає, щоб потреби усіх користувачів застосувань клієнта Kj у місткості процесорів задовольняв виділений фізичний сервер Ni;
|
|
(3) |
Обмеження (3) вимагає, щоб місткість каналів зв’язку виділеного сервера Ni забезпечувала ефективну роботу усіх застосувань, які обслуговують користувачів застосувань клієнта Kj;
|
|
(4) |
Обмеження (4) вимагає, щоб місткість оперативної пам'яті виділеного сервера Ni була достатньою для роботи усіх застосувань клієнта Kj;
|
|
(5) |
Обмеження (5) вимагає, щоб місткість дискової пам’яті виділеного сервера Ni була достатньою для роботи усіх застосувань клієнта Kj;
|
|
(6) |
Обмеження (6) вимагає, щоб кожний сервер виділявся не більше ніж для одного клієнта;
|
|
(7) |
Обмеження (7) вимагає, щоб для кожного клієнта виділявся точно один сервер;
|
|
(8) |
Обмеження (8) вимагає, щоб надійність виділеного сервера Ni забезпечувала вимоги до надійності клієнта Kj.
Задача 2. Якщо кластеризація серверів підтримується і для хостингової компанії важлива економія ресурсів, то виникає задача мінімізації витрат на підтримку тієї частини серверів, яка забезпечуватиме підтримку запитів користувачів клієнта. Тобто вибирається така мінімальна за витратами на їх підтримку підмножина серверів, які зможуть підтримати необхідну для задоволення вимог існуючих користувачів застосувань, причому кожному клієнту виділяється один фізичний сервер або кластер серверів.
Використовуючи введені позначення, критерій цієї задачі запишемо у такому вигляді:
|
|
(9) |
Мінімальне значення треба вибирати із рішень, які відповідають структурі булевих значень матриці R=|Rji|m×n та таким обмеженням:
|
|
(10) |
Обмеження (10) вимагає, щоб виділений сервер Ni чи кластер серверів задовольняв вимоги усіх користувачів застосувань клієнта Kj у процесорній місткості. Це обмеження має місце, якщо мова йде про кластер, створюваний для підвищенні продуктивності. Тут p – коефіцієнт падіння сумарної процесорної місткості кластера за рахунок необхідності підтримки взаємодії серверів кластера. Взагалі це обмеження повинне виконуватися для кожного сервера кластера, створюваного з метою підвищення надійності, але тоді коефіцієнт p набуває значення 1;
|
|
(11) |
Обмеження (11) вимагає, щоб виділений сервер Ni чи кластер серверів задовольняв вимоги усіх користувачів застосувань клієнта Kj у місткості каналів зв’язку;
|
|
(12) |
де α – коефіцієнт, що враховує додаткові витрати оперативної пам’яті при розміщенні застосувань на декількох серверах. Цей коефіцієнт підбирається на основі накопиченого досвіду з урахуванням специфіки застосувань. Використання цього коефіцієнта дозволяє складну задачу закріплення серверів і застосувань декомпозувати на дві підзадачі: закріплення серверів за клієнтами та розміщення екземплярів застосувань на виділених серверах. У загальному випадку при вирішенні другої підзадачі для деяких клієнтів може знадобитися повторне вирішення першої підзадачі з іншим значенням коефіцієнта α.
Обмеження (12) вимагає, щоб виділений сервер Ni чи кластер серверів задовольняв сумарні вимоги gSj до місткості оперативної пам'яті усіх застосувань клієнта Kj, якщо мова йде про кластер, створюваний для підвищенні продуктивності;
|
|
(13) |
Обмеження (13) вимагає, щоб виділений сервер Ni чи кожний сервер кластеру задовольняв сумарні вимоги gSj до місткості оперативної пам'яті усіх застосувань клієнта Kj, якщо мова йде про кластер, створюваний з метою підвищення надійності;
|
|
(14) |
Обмеження (14) вимагає, щоб виділений сервер Ni чи один з серверів кластера задовольняв вимоги gmaxj найвимогливішого щодо оперативної пам'яті застосування клієнта Kj, якщо мова йде про кластер, створюваний для підвищенні продуктивності. Якщо ж кластер створюється з метою підвищення надійності, то ця потреба має бути врахована для кожного сервера, але вона уже врахована обмеженням 13 для цього виду кластерів;
|
|
(15) |
де b – коефіцієнт, що враховує додаткові витрати пам’яті на жорстких дисках при розміщенні застосувань на декількох серверах. Рекомендації щодо вибору його значень аналогічні рекомендаціям щодо вибору коефіцієнта α.
Обмеження (15) вимагає, щоб виділений сервер Ni чи кластер серверів задовольняв сумарні вимоги jSj до місткості пам’яті жорстких дисків усіх застосувань клієнта Kj, якщо мова йде про кластер, створюваний для підвищенні продуктивності;
|
|
(16) |
Обмеження (16) вимагає, щоб виділений сервер Ni чи кожний сервер кластеру задовольняв сумарні вимоги jSj до місткості пам’яті жорстких дисків усіх застосувань клієнта Kj, якщо мова йде про кластер, створюваний з метою підвищення надійності;
|
|
(17) |
Обмеження (17) вимагає, щоб виділений сервер Ni чи один з серверів кластера задовольняв вимоги jmaxj найвимогливішого щодо пам’яті жорстких дисків застосування клієнта Kj, якщо мова йде про кластер, створюваний для підвищенні продуктивності. Якщо ж кластер створюється з метою підвищення надійності, то ця потреба має бути врахована для кожного сервера, але вона уже врахована обмеженням 16 для цього виду кластерів;
|
|
(18) |
Обмеження (18) вимагає, щоб кожний сервер виділявся не більше ніж для одного клієнта;
|
|
(19) |
Обмеження (15) вимагає, щоб для кожного клієнта виділялося не менше одного сервера;
|
|
(20) |
Обмеження (20) вимагає, щоб виділений сервер Ni чи кластер серверів задовольняв вимоги клієнта Kj до надійності. Тут функція f визначає підхід до визначення надійності кластера серверів у залежності від надійності серверів.
Для оцінювання надійності сервера (кластера) будемо застосовувати коефіцієнт готовності сервера (кластера). У залежності від того, з якою метою створюються кластери, обмеження (20) може набувати такого вигляду:
1) кластер створюється для забезпечення надійності. У цьому випадку, якщо взяти, наприклад побудову кластера на двох серверах, то значення функція f можна визначити за допомогою виразу (21).
|
|
(21) |
де Di, i = 1,2, – коефіцієнт готовності сервера Ni.
Тут вимоги застосувань клієнта Kj до місткості оперативної пам'яті і процесорної місткості повинні виконуватися для кожного сервера кластеру, тобто повинні мати місце обмеження (10), у якому коефіцієнт p набуває значення 1, і (13);
2) кластер створюється для забезпечення продуктивності. У цьому випадку продуктивність кластера визначається за допомогою виразу, наведеного у лівій частині нерівності обмеження (10). Тоді обмеження (10) повинне виконуватися для вимог усіх застосувань клієнта Kj, а вимоги до оперативної та дискової пам’яті враховуються обмеженнями (12), (14) і (15), (17) відповідно;
3) кластер створюється для забезпечення продуктивності і надійності за проміжною схемою n + 1, коли n серверів працює на підвищення продуктивності, а 1 сервер використовується для підвищення надійності. Наприклад, розглянемо наведений на рис.3 варіант схеми n +1, де n = 1, із застосуваннями A1 і A2, причому застосування A1 є більш пріоритетним.
A2 A2 A1
![]()
![]()
|
![]()
 |
Тоді надійність застосування А1, як більш пріоритетного, визначається надійністю кластера, а надійність застосування А2, яке є менш пріоритетним, визначається надійністю одночасного функціонування обох серверів.
Тобто у цьому випадку потрібно використовувати поняття надійності сервісів, взявши за основу вираз для визначення продуктивності кластера на основі лівої частини нерівності із (10) і узагальнення схеми, наведеної на рис.3.
Для розрахунку надійності кластерів тоді можна взяти за основу формулу (21), у якій ![]() – це коефіцієнт готовності сервера для забезпечення надійності і
– це коефіцієнт готовності сервера для забезпечення надійності і ![]() – це найменший із коефіцієнтів готовності серверів із групи n.
– це найменший із коефіцієнтів готовності серверів із групи n.
Для розрахунку надійності застосувань за цією схемою можна застосувати формули розрахунку продуктивності для кластерів продуктивності.
Задача 2’. Досить цікавий випадок становить задача, коли за клієнтом з метою підвищення продуктивності шляхом балансування навантаження закріплюється декілька серверів, на яких встановлюється однаковий набір екземплярів застосувань. В цьому випадку вимоги до об’єму ресурсів, що не залежать від навантаження, повинні задовольнятись на кожному з цих серверів, а вимоги до ресурсів, що залежать від навантаження, мають забезпечуватись сумарною ємністю ресурсів цих серверів:
|
|
(22) |
Обмеження (22) вимагає, щоб потреби усіх застосувань клієнта Kj у кількості процесорного часу задовольнялись сумарними процесорними ресурсами серверів;
|
|
(23) |
Обмеження (23) вимагає, щоб сумарна місткість каналів зв’язку виділених для користувача Kj серверів забезпечувала ефективну роботу усіх застосувань. Вимоги, що до незалежних від навантаження ресурсів, а саме оперативної та дискової пам’яті серверів формулюються у вигляді (4) та (5) відповідно. Взявши за критерій вираз (9) та обмеження (4) – (7), (18) – (20), (22), (23), отримуємо лінійну або нелінійну задачу булевого програмування в залежності від наявності вимог клієнтів до надійності.
Задача 3. Якщо для хостингової компанії важлива економія ресурсів, а витрати на реалізацію переходу до нового оптимального плану закріплення серверів порівнювані за витратами на підтримку серверів, то виникає задача мінімізації сумарних витрат на підтримку серверів і реалізацію переходу до нового плану закріплення серверів. Тобто вибирається така мінімальна за сумою витрат на реалізацію переходу до нового оптимального плану закріплення серверів і на їх підтримку підмножина серверів, які зможуть підтримати необхідну для задоволення вимог існуючих користувачів множину екземплярів застосувань. З використанням введених вище позначень критерій цієї задачі можна записати у вигляді (17).
|
|
(24) |
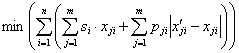
У виразі (24) pji позначає витрати, які пов’язані з переходом до нового оптимального плану закріплення серверів у частині, що стосується клієнта Kj і сервера Ni, ![]() – значення змінної
– значення змінної ![]() у попередньому плані. Витрати pji враховуються, якщо значення нового і попереднього планів у позиції (j,i) відрізняються.
у попередньому плані. Витрати pji враховуються, якщо значення нового і попереднього планів у позиції (j,i) відрізняються.
Мінімальне значення треба вибирати із рішень, які відповідають структурі булевих значень матриці R=|Rji|m×n та задовольняють наведені вище обмеження (10) - (20) з урахуванням зауважень до вибору обмежень для різних підходів до створення кластерів, наведених у постановці задачі 2.
Наведені вище задачі оптимізації розміщень – це лінійні та нелінійні варіанти задачі булевого програмування. Оскільки обійти перебірні методи їх вирішення не можна, виправданим буде використання евристичних методів або методів «м’яких» обчислень, насамперед генетичних алгоритмів, застосування яких дає контрольоване наближення до точного результату [13 - 14].
6. Алгоритм вирішення задачі. Для вирішення наведених вище задач оптимального розміщення пропонуються варіанти генетичного алгоритму і евристичного алгоритму, який враховує специфіку критеріїв і обмежень. Крім того, пропонується комбінований алгоритм, побудований на використанні методів вирішення задач лінійного програмування і неявного перебору.
Варіанти генетичного алгоритму. Розглянемо розроблений на основі основоположних праць універсальний варіант такого алгоритму для задачі 2, яка є складнішою з огляду на не лінійність її обмежень. Цей варіант можна досить легко модифікувати для кожної з наведених задач.
Крок 0. Задаємо точність обчислень s. Установлюємо i = 0. Утворення випадкової початкової популяції Pk(0)={p1(0),...,pk(0)} з урахуванням можливого відсіювання під час перевірки обмежень.
Крок 1. Оцінюємо кожний ланцюжок популяції щодо виконання обмежень відповідної задачі, наприклад, для задачі 2 обмежень (10) - (20). Для тих ланцюжків pq(0), для яких обмеження виконуються, виконується оцінка f(pq(0)) цільової функції відповідної задачі, наприклад, для задачі 1 це (9), і вибір найкращого рішення.
Крок 2. Відбираємо представників для нової популяції (ланцюжків з найкращим значенням функції f(pq(0)).
Крок 3. l=l+1. Утворюємо нову популяцію застосуванням оператора рекомбінації.
Крок 4. Поліпшуємо популяцію застосуванням оператора мутації.
Крок 5. Оцінюємо кожний ланцюжок популяції щодо виконання обмежень і функцію f(pq(l)), якщо обмеження виконується.
Крок 6. Якщо рішення краще попереднього із заданою точністю s, то завершуємо виконання алгоритму, в супротивному випадку повертаємося на крок 3.
Вибирається найкраще рішення в утвореній популяції Pk(l).
У наведеному варіанті генетичного алгоритму кожний ланцюжок (особина) будь-якої популяції становить двійковий вектор довжини t = m×n, яка визначається кількістю фізичних серверів і клієнтів. Елемент q вектора набуває значення 0 або 1 відповідних змінних ![]() . Довжина ланцюжків постійна.
. Довжина ланцюжків постійна.
Відбір особини для нової популяції виконується на основі ранжування за значенням цільової функції особин попередньої популяції, причому ранжуються лише особини, які задовольняють ресурсним та іншим обмеженням.
Для рекомбінування застосовується одноточковий кросинговер з випадковим вибором точки кросинговеру. Реалізація мутацій здійснюється на основі схеми інверсії ділянок ланцюжків.
Варіанти евристичного алгоритму. Ці алгоритми базуються на інтуїтивних уявленнях, які враховують роль залежних і незалежних, з яких найкритичніший – оперативна пам’ять, ресурсів, і вигляді критерію. Оскільки процесорну місткість можна забезпечити сукупно декількома серверами, а оперативну пам’ять лише одним сервером, то буде логічним спершу розмістити застосування, які мають вищі потреби в оперативній пам'яті, чим в процесорному часі. Взявши це за правило, далі необхідно лише врахувати особливості критерію. Кожному фізичному серверу Ni припишемо коефіцієнт Ri, значенням якого приймемо відношення процесорної місткості сервера Ni до місткості його оперативної пам’яті, кожному клієнту Kj – коефіцієнт rj, значенням якого приймемо відношення вимог застосувань клієнта Kj до процесорної місткості до сумарних вимог gSj застосувань клієнта Kj до місткості оперативної пам’яті.
Продемонструємо варіант евристичного алгоритму на прикладі задачі 2. З очевидними застереженнями його можна модифікувати для інших задач.
Попередній етап для будь-якого з наведених нижче варіантів евристичного алгоритму полягає у сортуванні фізичних серверів за значенням їх коефіцієнта R у порядку зростання і сортуванні клієнтів за значенням їх коефіцієнта r у порядку спадання.
Евристичний алгоритм для задачі 1. Попередній етап виконано.
Крок 1. Пошук клієнта, який має найменше значення коефіцієнта r.
Крок 2. Пошук сервера з найбільшим значенням коефіцієнта R.
Крок 3. Якщо для вибраних сервера і клієнта не виконуються обмеження задачі 2 стосовно вимог gmaxj найвимогливішого щодо оперативної пам'яті застосування клієнта Kj, то повертаємося на крок 2 для пошуку наступного сервера.
Крок 4. Якщо для вибраних сервера і клієнта не виконуються інші ресурсні обмеження задачі 2, то повертаємося на крок 2 для пошуку наступного сервера.
Крок 5. Якщо для вибраних сервера і клієнта виконуються обмеження задачі 2, причому залежні від навантаження вимоги повністю задоволені, то переходимо на крок 6. Якщо виконуються обмеження задачі 2, але сервер не може повністю задовольнити залежні від навантаження вимоги застосування, то переходимо на крок 7.
Крок 6. Клієнт вилучається із упорядкованого списку клієнтів, коригується коефіцієнт R сервера і він вбудовується в упорядкований список серверів відповідно до нового значення коефіцієнта. Перехід до кроку 8.
Крок 7. Ресурси сервера, що залишилися, дістаються застосуванням клієнта і сервер вилучається із упорядкованого списку серверів. Переходимо до кроку 2.
Крок 8. Якщо упорядкований список клієнтів порожній, то кінець роботи алгоритму, інакше перехід до кроку 1.
Обчислювальна складність евристичного алгоритму становить m×n.
Для інших критеріїв використовується інша логіка вибору серверів у їх впорядкованому списку.
Комбінований алгоритм. Для лінійних задач булевого програмування, до яких зведені задачі закріплення серверів за клієнтами, запропоновані ряд методів, в першу чергу неявного перебору, які використовують для скорочення кількості вариантів, які перебираються, крім відомих прийомів, зручний вигляд обмежень задачі. Однак, специфіка матриці обмежень задачі 1 не надто сприяє широкому застосуванню традиційних прийомів скорочення перебору. У той же час вона підштовхує до пошуку комбінованого підходу до вирішення задачі. Порівняно невелика кількість обмежень передбачає застосування ефективних методів вирішення задачі лінійного програмування, оскільки її рішення будуть містити невелику кількість нецілочисельних компонентів. Схема перебору застосовується саме до зазначених нецілочисельних компонентів. Саме такий підхід з обнадійливими результатами був застосований до лінійних задач булевого програмування у праці [1]. В основу підходу покладена схема, яка включає такі етапи:
1) Вирішення задачі 1 без умов цілочисельності змінних;
2) Підстановка цілочисельних компонентів одержаного рішення у вихідну задачу;
3) Вирішення одержаної задачі методом неявного перебору.
На жаль, зростання кількості змінних вирішення задачі першого етапу ускладнюється, оскільки різко зростають вимоги до пам’яті і об’єму обчислень. Сучасний стан лінійного програмування дозволяє вирішувати задачі значно більшої вимірності за допомогою декомпозиції і афіно-масштабуючих алгоритмів [15 - 17].
7 Результати впровадження. Запропоновані методи були досліджені стосовно одержання розв’язків близьких до оптимального і часу роботи. Розрахунки виконувалися з різними варіантами кількостей фізичних серверів і клієнтів. При цьому вимоги клієнтів і характеристики фізичних серверів змінювалися. Було проведено розрахунки для більш ніж тисячі варіантів вхідних даних. Вхідні дані генерувалися випадковим чином.
Результати продемонстрували працездатність евристичних методів і варіантів генетичного алгоритму для усіх задач. При цьому евристичні алгоритми переважно одержували розв’язок швидше, але з меншим наближенням до оптимуму.
Для задачі 1 комбінований алгоритм зайняв проміжне місце, поступаючись у часі евристичному і генетичному, він давав точне рішення у межах можливостей моделюючої системи.
Розроблені в статті моделі і методи були покладені в основу реалізації функцій оптимізації створеної в НТУУ «КПІ» системи управління ІТ-інфраструктурою SmartBase.ITSControl. Ця система, яка реалізована на основі платформи SmartBase [18], впроваджена в одній великій розподіленій ІТС і використовується в декількох проектах, які перебувають на стадії проектування.
Висновки. В статті запропоновано підхід до планування завантаження і використання ресурсів ЦОД в умовах віртуального хостингу. Розроблені моделі і методи використані при створенні СУІ. Від попередніх технологій управління навантаженням і використанням ресурсів його відрізняють надання адміністраторам можливості використовувати декілька критеріїв, врахування декількох типів ресурсів, гнучкість у переході до нових планів розміщення екземплярів застосувань.
Подальший розвиток досліджень пов’язаний з розробленням моделей і алгоритмів інших моделей хостингу, що дозволить розширити множину ситуацій, в яких може застосовуватися створена СУІ SmartBase.ITSControl.
ЛІТЕРАТУРА
1. Павлов А.А. Информационные технологии и алгоритмизация в управлении / А.А.Павлов, С.Ф.Теленик. – К.: Техника, 2002. – 344 с.
2. Теленик С.Ф. Система управління інформаційно-телекомунікаційною системою корпоративної АСУ / С.Ф.Теленик, О.І Ролік, М.М.Букасов, Р.Л.Соколовський // Вісник НТУУ «КПІ». Інформатика, управління та обчислювальна техніка. – К.: «ВЕК+». – 2006. – №45. – С. 112–126.
3. Vinoski S. Service Discovery 101 / S.Vinoski // IEEE Internet Computing.- Vol. 7.-#1.- 2005.- P. 405–426.
4. Frenkel D. MDM: Applying MDA to Enterprise Computing / D.Frenkel.- John Wiley & Sons, 2003. - 240 p.
5. Wolf J. On balancing load in a clustered web farm / J. Wolf, P. Yu. // ACM Transactions on Internet Technology. - 2001. - Vol. 1.- # 2.- P. 231–261.
6. Ardagna D. SLA based profit optimization in multi-tier web application systems / D. Ardagna, M. Trubian, L. Zhang / Proc. of Int’l Conference On Service Oriented Computing, New York, NY. 2004. P. 173–182.
7. Kimbrel T. Dynamic application placement under service and memory constraints / T. Kimbrel, M. Steinder, M. Sviridenko, A. Tantawi / Proc. of Int’l Workshop on Efficient and Experimental Algorithms, Santorini Island, Greece, May 2005. P.1-12.
8. Теленик С.Ф. Управління ресурсами центрів оброблення даних / С.Ф. Теленик, О.І. Ролік, М.М. Букасов, К.О. Крижова // Вісник ЛНУ імені Івана Франка. – 2009. – №11. – С. 103 – 119.
9. Теленик С.Ф. Моделі управління розподілом обмежених ресурсів в інформаційно-телекомунікаційній мережі / С.Ф. Теленик, О.І. Ролік, М.М. Букасов // Вісник НТУУ «КПІ». Інформатика, управління та обчислювальна техніка. – К.: Екотех. – 2006. – №44. – С. 243 – 246.
10. Теленик С.Ф Забезпечення процесів діяльності з визначеним рівнем надійності в ІТС спеціального призначення / С.Ф. Теленик, О.І. Ролік, П.І. Терещенко, М.М. Букасов // Зб. наук. праць ВІТІ НТУУ „КПІ”.- №3.- К., 2007.- С. 134 – 138.
11. Теленик С.Ф. Метод розподілу ресурсів між проектами / С.Ф. Теленик, П.І. Бідюк, О.А. Амонс, К.О. Крижова // Вісник НТУУ «КПІ». Інформатика, управління та обчислювальна техніка. – К.: «ВЕК+». – 2008. – №48. – С. 33 – 41.
12. Теленик С.Ф. Метод формування логічного висновку із залученням експертного комітету / С.Ф. Теленик, П.І. Бідюк, Л.О. Коршевнюк, В.С. Хмелюк // Проблеми програмування. – 2008. – №4. – С. 73 – 83.
13. Холланд Дж. Генетические алгоритмы / Дж. Холланд // В мире науки.- 1992.- №9-10.- С. 32 – 40.
14. Leung K.-S. A new model of simulated evolutionary computation – convergence analysis and specifications / K.-S. Leung, Q.-H. Duan, Z.-B. Xu, C.K.Wong // IEEE Transactions on evolutionary computation.- Vol.5.- #1.- 2001.- P. 3 – 16.
15. Лэсдон Л.С. Оптимизация больших систем / Л.С. Лэсдон. – М.: Наука, 1975.-432с.
16. Дикин И.И. Итеративное решение задач линейного и квадратичного программирования / И.И. Дикин // Доклады АН СССР.- 1967.- Т. 174.- С. 747 – 748.
17. Еремин И.И. Теория линейной оптимизации / И.И. Еремин.- Екатеринбург: Екатеринбург, 1999.- 312 с.
18. Теленик С.Ф. Швидке розроблення застосувань в адаптивній технології SmartBase / С.Ф. Теленик, О.А. Амонс, В.С. Хмелюк, К.О. Крижова // Проблеми програмування. – 2006. – №1–2. Спец. випуск. – С. 299 – 305.
Ответы на вопросы [_Задать вопроос_]
Читайте также
Информационно-управляющие комплексы и системы
Теленик С.Ф., Ролік О.І., Букасов М.М., Андросов С.А. Генетичні алгоритми вирішення задач управління ресурсами і навантаженням центрів оброблення данихБогушевский В.С., Сухенко В.Ю., Сергеева Е.А., Жук С.В. Реализация модели управления конвертерной плавкой в системе принятия решений
Бень А.П., Терещенкова О.В. Применение комбинированных сетевых методов планирования в судоремонтной отрасли
Цмоць І. Г., Демида Б.А., Подольський М.Р. Методи проектування спеціалізованих комп’ютерних систем управління та обробки сигналів у реально-му час
Селякова С. М. Структура інтелектуальної системи управління збиральною кампанією
Еременко А.П., Передерий В.И. Принятие решений в автоматизированных системах с учетом психофункциональных характеристик оператора на основе генетических алгоритмов
Львов М.С. Алгоритм перевірки правильності границь змінення змінних у послідовних програмах
Ляшенко Е.Н. Анализ пожарной опасности сосновых насаждений в зоне Нижне-днепровских песков – самой большой пустыни в Европе
Кучеров Д.П., Копылова З.Н. Принципы построения интеллектуального автору-левого
Касаткина Н.В., Танянский С.С., Филатов В.А. Методы хранения и обработки нечетких данных в среде реляционных систем
Ходаков В.Е., Жарикова М.В., Ляшенко Е.Н. Применение когнитивного подхода для решения задачи поддержки принятия управленческих решений при ликвидации лесных пожаров
Гончаренко А.В. Моделювання впливу ентропії суб’єктивних переваг на прийняття рішень стосовно ремонту суднової енергетичної установки
Фарионова Н.А. Системный подход построения алгоритмов и моделей систем поддержки принятия решений при возникновении нештатных ситуаций
Биленко М.С., Серов А.В., Рожков С.А., Буглов О.А. Многоканальная система контроля качества текстильных материалов
Мотылев K.И., Михайлов M.В., Паслен В.В. Обработка избыточной траекторной информации в измерительно-вычислительных системах
Гончаренко А.В. Вплив суб’єктивних переваг на показники роботи суднової енергетичної установки
Гульовата Х.Г., Цмоць І.Г., Пелешко Д.Д. Архітектура автоматизованої системи моніторингу і дослідження характеристик мінеральних вод
Соломаха А.В. Разработка метода упреждающей компенсации искажений статорного напряжения ад, вносимых выходными силовыми фильтрами
ПотапенкоЕ.М., Казурова А.Е. Высокоточное управление упругой электромеханической системой с нелинейным трением.
Кузьменко А.С., Коломіц Г.В., Сушенцев О.О. Результати розробки методу еквівалентування функціональних особливостей fuzzy-контролерів
Кравчук А. Ф., Ладанюк А.П., Прокопенко Ю.В. Алгоритм ситуационного управления процессом кристаллизации сахара в вакуум-аппарате периодического действия с механическим циркулятором
Абрамов Г.С., Иванов П.И., Купавский И.С., Павленко И.Г. Разработка навигационного комплекса для автоматического наведения на цель системы груз-управляемый парашют
Литвиненко В.И., Четырин С.П. Компенсация ошибок оператора в контуре управления следящей системы на основе синтезируемых вейвелет-сетей
Бардачев Ю.Н., Дидык А.А. Использование положений теории опасности в искусственных иммунных системах
Рожков С.О., Кузьміна Т.О., Валько П.М. Інформаційна база як основа для створення асортименту лляних виробів.
Ускач А.Ф., Становский А.Л., Носов П.С. Разработка модели автоматизированной системы управления учебным процессом
Мазурок Т.Л., Тодорцев Ю.К. Актуальные направления интеллектуализации системы управления процессом обучения.
Ускач А.Ф., Гогунский В.Д., Яковенко А.Е. Модели задачи распределения в теории расписания.
Сідлецький В.М., Ельперін І.В., Ладанюк А.П. Розробка алгоритмів підсистеми підтримки прийняття рішень для контролю якості роботи дифузійного відділення.
Пономаренко Л.А., Меликов А.З., Нагиев Ф.Н. Анализ системы обслуживания с различными уровнями пространственных и временных приоритетов.
Коршевнюк Л.О. Застосування комітетами експертів системи нечіткого логічного виводу із зваженою істинністю.. – С. 73 – 79.
Кирюшатова Т.Г., Григорова А.А Влияние направленности отдельных операторов и направленности всей группы на конечный результат выполнения поставленной задачи.
Петрушенко А.М., Хохлов В.А., Петрушенко І.А. Про підключення до мови САА/Д деяких засобів паралельного програмування пакету МРІСН.
Ходаков В.Е., Граб М.В., Ляшенко Е.Н. Структура и принципы функционирования системы поддержки принятия решений при ликвидации лесных пожаров на базе новых геоинформационных технологий.
Сидорук М.В., Сидорук В.В. Информационные системы управления корпорацией в решении задач разработки бюджета.
Нагорный Ю.И. Решение задачи автоматизированного расчета надежности иасуп с использованием модифицированного метода вероятностной логики
Козак Ю.А. Колчин Р.В. Модель информационного обмена в автоматизированной системе управления запасами материальных ресурсов в двухуровневой логистической системе
Гожий А.П., Коваленко И.И. Системные технологии генерации и анализа сценариев
Вайсман В.А., Гогунский В.Д., Руденко С.В. Формирование структур организационного управления проектами
Бараненко Р.В., Шаганян С.М., Дячук М.В. Аналіз алгоритмів взаємних виключень критичних інтервалів процесів у розподілених системах
Бабенко Н.И., Бабичев С.А. Яблуновская Ю.А. Автоматизированная информационная система управления учебным заведением
Яковенко А.Е. Проектирование автоматизированных систем принятия решений в условиях адаптивного обучения с учетом требований болонского процесса
Бараненко Р.В Лінеаризація шкали і збільшення діапазону вимірювання ємностей резонансних вимірювачів
Головащенко Н.В. Математичні характеристики шумоподібно кодованих сиг-налів.
Шерстюк В.Г. Формальная модель гибридной сценарно-прецедентной СППР.
Шекета В.І. Застосування процедури Append при аналізі абстрактних типів даних модифікаційних запитів.
Цмоць І.Г. Алгоритми та матричні НВІС-структури пристроїв ділення для комп'-ютерних систем реального часу.
Кухаренко С.В., Балтовский А.А. Решение задачи календарного планирования с использованием эвристических алгоритмов.
Бараненко Р.В., Козел В.Н., Дроздова Е.А., Плотников А.О. Оптимизация рабо-ты корпоративных компьютерных сетей.
Нестеренко С.А., Бадр Яароб, Шапорин Р.О. Метод расчета сетевых транзакций абонентов локальных компьютерных сетей.
Григорова А.А., Чёрный С. Г. Формирование современной информационно-аналитической системы для поддержки принятия решений.
Шаганян С.Н., Бараненко Р.В. Реализация взаимных исключений критических интервалов как одного из видов синхронизации доступа процессов к ресурсам в ЭВМ
Орлов В.В. Оценка мощности случайного сигнала на основе корреляционной пространственной обработки
Коджа Т.И., Гогунский В.Д. Эффективность применения методов нечеткой логики в тестировании.
Головащенко Н.В., Боярчук В.П. Аппаратурный состав для улучшения свойств трактов приёма – передачи информации в системах промышленной автоматики.