УДК 534.78:519.217.2
АНАЛІЗ ТЕНДЕНЦІЙ ПОБУДОВИ
СИСТЕМ МОВНОГО ІНТЕРФЕЙСУ
Фаніна Л.О.
Введення.
Мова є найбільш природною формою людського спілкування, тому реалізація інтерфейсу на основі аналізу мовної інформації являє собою перспективний напрямок розвитку інтелектуальних систем управління.
На перший погляд визначення мовного інтерфейсу може здаватися досить простим: людина вимовляє фразу, на яку технічна система реагує адекватно. Однак за досить простою ідеєю криються величезні складності, рішення яких знаходиться на стику багатьох галузей науки і розгадки таємниць функціонування людського інтелекту. Інтерес до даної проблеми виник досить давно, з появою обчислювальної техніки він спалахнув з новою силою. Мало кому відомо, що ще в 1939 році в Ленінградському державному університеті Л.Л. Мясніковим була продемонстрована перша у світі автоматична система розпізнавання мови (СРМ). В п'ятидесяті-шістдесяті роки, час романтики кібернетики, здавалося, що з комп'ютером можна буде спілкуватися за допомогою мови вже через 10-15 років, у кінці вісімдесятих років – рішення проблеми затяглось ще на десятиліття. Як можна побачити, безпосереднє впровадження мовного інтерфейсу в повсякденне життя звичайного користувача поки відкладається. Однак не можна недооцінювати наявний у даний час деякий прогрес, постійно збільшується попит на продукти мовної технології. Програми і системи, що володіють засобами мовного введення інформації, одержують усе більше поширення, але, з огляду на всі недосконалості, варто розглядати перспективи розвитку вузькоспрямованих або спеціалізованих систем, що мають чітке застосування:
· Управління системами життєзабезпечення для людей з обмеженими фізичними можливостями та побудови систем інтелектуалізації житла, так звані SmartHome.
· Впровадження голосового вводу інформації у компактні мобільні термінали та міні комп’ютери.
· Розробка інформаційно-довідкових служб різного призначення, в яких клієнт запитує довідки, данні, що його цікавлять й одержує інформацію в мовній або іншій формі; телефоні лінії підтримки клієнтів, електронна комерція.
· Автоматизовані системи заповнення анкет та шаблонних інформаційних листів.
· Розробка на сучасних технологіях пошуку в інформаційних мережах мовної інформації по заданих ключових словах або проблематиці.
· Можливість створення робота-мікроскопу для проведення тонких хірургічних утручань, коли лікар не відволікаючись від розглядання через мікроскоп хірургічного поля, може керувати рухом та настроюванням мікроскопу.
· Можливість використання технології розпізнавання та розуміння мовної інформації для створення автоматичних систем переводу з одної мови на іншу, що працює у реальному часі.
· Створення комплексу програмних засобів для відтворення спотворених та зашумлених мовних повідомлень.
Постановка задачі.
Задача розпізнавання мови складається в
точному й ефективному відтворенні вимовленого мовного сигналу ![]() . У загальному
випадку, її рішення полягає в послідовному порівнянні з еталонами, що задані
словником системи розпізнавання мови.
. У загальному
випадку, її рішення полягає в послідовному порівнянні з еталонами, що задані
словником системи розпізнавання мови.
Схематично процес розпізнавання можна представити так:

Рис. 1 Концептуальна схема розпізнавання мови
Таким чином, невідомому висловленню ![]() , що задано вектором ознак
, що задано вектором ознак ![]() , буде поставлена у
відповідність послідовність моделей
, буде поставлена у
відповідність послідовність моделей ![]() . Знайдена послідовність повинна мати
найбільшу апостеріорну імовірність. Відповідно можна використати формулу
Байєса, що дозволяє представити апостеріорну імовірність
. Знайдена послідовність повинна мати
найбільшу апостеріорну імовірність. Відповідно можна використати формулу
Байєса, що дозволяє представити апостеріорну імовірність ![]() як
як
![]() .
.
Розрахунок апостеріорної імовірності розбивається на два етапи:
розрахунок функції правдоподібності ![]() при заданій моделі
при заданій моделі ![]() , що залежить від акустичних
даних, та оцінка апріорної імовірності
, що залежить від акустичних
даних, та оцінка апріорної імовірності ![]() . На етапі розпізнавання
. На етапі розпізнавання ![]() , як правило, є
константою,
, як правило, є
константою, ![]() легко
визначається на основі лінгвістичного аналізу мови, тому основна складність
полягає в визначенні функції
легко
визначається на основі лінгвістичного аналізу мови, тому основна складність
полягає в визначенні функції ![]() [1].
[1].
Для визначення векторів ознак ![]() використовуються різноманітні методи
первинної обробки мовних сигналів, що як і підходи до побудови декодерів й
методи прийняття рішень протягом часу змінювались.
використовуються різноманітні методи
первинної обробки мовних сигналів, що як і підходи до побудови декодерів й
методи прийняття рішень протягом часу змінювались.
Основні тенденції побудови і розвитку систем розпізнавання мови можна представити як
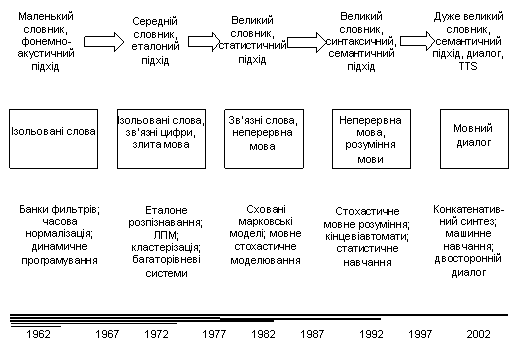
Рис. 2 Етапи розвитку СРМ
Розглянемо основні підходи до реалізації систем автоматичного розпізнавання мови.
Первинна обробка мовних сигналів.
Полягає у виділенні значимої для розпізнавання інформації, усунення варіантності, як диктора, так і навколишнього середовища, стиснення сигналу.
Методи аналізу мовних сигналів, тобто безпосереднього виділення ознак, поділяються на три групи [2].
1. Параметричні методи, що засновані на представленні мовного сигналу як реалізації деякого процесу в часі і виділення яких-небудь параметрів цього процесу, найчастіше пов'язаних з його спектральними характеристиками:
· спектрально-полосні методи;
· ортогональні методи;
· кореляційні методи;
· метод обчислення спектра за допомогою швидкого перетворення Фур'є;
· методи лінійного передбачення мови (ЛПМ);
· методи, пов'язані з виділенням р-параметра (миттєвої частоти переходів через нуль);
· часові методи, засновані на аналізі розподілу тривалості інтервалів між переходами через нуль або екстремумами мовного сигналу;
· використання нелінійного перетворення і фазові співвідношення мовного сигналу;
· застосування вейвлет-перетворення для моделювання мовних сигналів.
2. Фонетичні методи, які спираються на теорію мовотворення. Суть їх полягає у виділенні ознак, що характеризують спосіб артикуляції. Фонетичні методи аналізу мовних сигналів можуть розглядатися як перший рівень розпізнавання мови, тому що більшість з них засновано на деяких перетвореннях первинних ознак мовних сигналів.
3. Неакустичні методи. Вони по своїй меті примикають до фонетичних і складаються у виділенні інформації про процеси, що супроводять артикуляцію.
Еталонне розпізнавання.
Цей метод заснований на порівнянні деяких характеристик мови (енергетичних, спектральних тощо). В більшості випадків за еталони приймаються цілі слова. Даний метод зручний для використання в системах з обмеженим словником (наприклад, командні системи).
Прикладом реалізації таких систем можна розглядати найпростіші (кореляційні) детектори. На рис. 3 представлена структурна схема обробки мовного сигналу в системі розпізнавання мови на основі кореляційного аналізу [3].
Після визначення моментів початку і закінчення слів на основі методів обробки в часовій області оцінюються перші вісім коефіцієнтів кореляції зі швидкістю 67 разів/с. Для компенсації перекручування спектра, обчислюється усереднений спектр на великому інтервалі часу, що досягалося усередненням коефіцієнтів кореляції по усій фазі і припасуванням до усередненого по фазі спектрові двополюсної моделі. Параметри двополюсної моделі використовуються для побудови зворотного фільтра. Середній по фазі спектр потім нормується по входу шляхом згортки початкових і коефіцієнтів кореляції імпульсної характеристики зворотного фільтра. Перші шість нормованих автокореляційних коефіцієнтів використовуються потім як для створення еталонних зразків, так і для розпізнавання.
Після нормалізації спектра починається процедура розпізнавання. Невідома фраза порівнюється з кожним еталоном з наявних у файлі. Порівняння відбувається на основі міри розрізнення в просторі параметрів лінійного передбачення мови. Ця міра використовується і для динамічного узгодження часового масштабу вхідної фрази при мінімізації відстані з кожної з еталонних фраз.
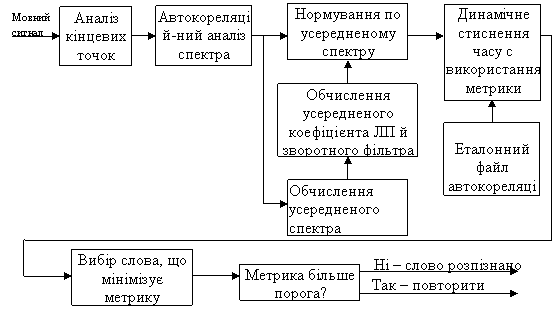
Рис. 3 Структурна схема СРМ на основі кореляційного аналізу
На основі обчислення відстаней до кожного слова зі словника вибирається те слово, для якого отримана мінімальна відстань. Якщо абсолютне значення відстані перевищує деякий поріг, то рішення не приймається. У цьому випадку вибирається інше слово з мінімальною відстанню, воно приймається як рішення і надходить на вихід системи розпізнавання.
Ця система досліджувалася [3] з використанням двох різних словників (обсягом приблизно 120 слів) і давала 97.3% правильного розпізнавання слів, однак не відрізнялася високою швидкодією і вимагала тривалого і ретельного навчання.
Багаторівневий фонемно-орієнтований метод.
Заснований на виділенні фонем з потоку мови.
Текст, як відомо, складається з букв, слів, речень, - тобто він дискретний. Мова ж у нормальних умовах звучить разом. Людська мова, на відміну від тексту, зовсім не складається з букв. Відомо, що це слово "мама" складається з чотирьох букв, однак на фонограмі (рис. 4) чітко видно, що насправді, воно складається не з чотирьох, а тільки з двох звуків: очевидно, це ті звуки, які можна виразити складами "ма" і "ма".
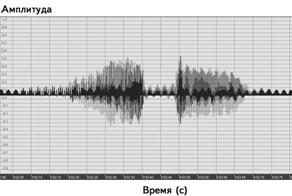
Рис. 4 Фонограма слова "мама"
Люди вже досить давно догадалися про те, що елементарні звуки, з яких складається мова, не еквівалентні буквам. Тому ввели поняття фонеми для позначення елементарних звуків мови. Хоча дотепер фахівці ніяк не можуть вирішити - скільки ж усього різних фонем існує. У лінгвістичній науці є цілий розділ - фонетика. Для кожної мови існує свій кінцевий набір фонем. В українській мові по одним біля 40 фонеми, по іншим - більш сотні.
Розглянемо модель побудови системи розпізнавання мови заснованої на фонемно-орієнтованому підході (рис.5).
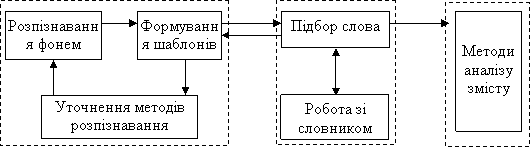
Рис. 5 Модель фонемно-орієнтованої СРМ
Зі списку фонем розпізнаних з визначеною точністю, складається шаблон, що передається на наступний рівень, де по ньому відбувається підбор найбільш підходящого слова і передача інформації про вибір на більш високий рівень для подальшого аналізу і на нижній, для підстроювання системи на конкретного користувача. Перевагою такої моделі побудови є висока адаптивність, що дає можливість динамічного самопідстроювання системи на диктора, і багаторівнева система перевірок, що підвищує точність роботи [4].
Експертні системи.
Системи з різними засобами формування й обробки бази знань.
Прикладом побудови таких систем може послужити система ROBOTRON, яка зображена на малюнку 6.
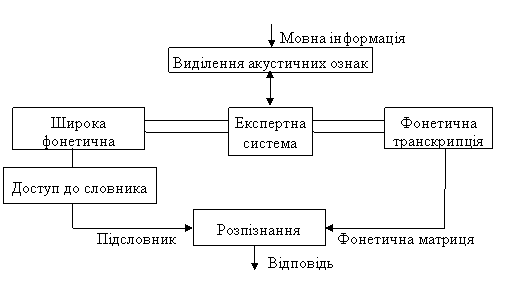
Рис. 6 Схема блоку розпізнавання системи ROBOTRON
Система розроблена в інституті інформатики Дрездена [5] й призначена для розпізнавання злитої мови. Вона дозволяє оброблювати мовну послідовність слів з необмеженою тривалістю без додаткової інформації о межах слів. Розроблена для дослідження та оптимізації процесів розпізнавання мови і навчання.
Складається з аналізатора, математичного забезпечення, блоку стиснення інформації, блоку розпізнавання та алгоритму навчання.
Але побудова й обробка сугубо баз знань не є максимально ефективними, що до вирішення проблем розпізнавання, тому доводиться знаходить інші математичні підходи.
Сховані марковські моделі.
В даний час є одним з найбільш ефективних підходів до побудови систем автоматичного розпізнавання мови.
Той факт, що мова призначена для передачі, а
отже, і для захисту інформації, дозволяє розглядати її як деякий код, а мовний
потік – як послідовність деяких кодових пакетів. Неважливо, що є елементом
цього коду – фонеми, склади або цілі слова, значення має лише те, що
імовірність появи будь-якого елемента коду залежить від деякого числа
попередніх елементів. Таким чином, мова породжується марковським джерелом, а
мовний код є випадковим. Для реалізації цього підходу застосовується так звана
„схована марківська модель” (Hidden Markov Model) ![]() , в які дозволяються переходи тільки у
наступний чи поточний стан.
, в які дозволяються переходи тільки у
наступний чи поточний стан.
Схованою марківською моделлю (СММ) зветься марківський процес, що не спостерігається безпосередньо. Результати дії цього процесу спотворюються випадковим процесом і лише після цього стають доступними для спостережень. Параметрами схованої марківської моделі є:
· можливі стани процесу;
· ймовірність переходу з одного стану в інший;
· ймовірність спотворення стану, що спостерігається.
Загальна теорія схованих марківських моделей може бути легко адаптована для рішення окремих задач розпізнавання мови. Конкретні вимоги й умови кожної задачі знімають або, навпаки, додатково накладають деякі обмеження на СММ, що дозволяє у визначених межах варіювати обчислювальну складність системи і вибирати найбільш ефективний алгоритм навчання моделі. Адекватність СММ мовному сигналові досягається за рахунок удалого вибору стаціонарних ділянок сигналу і визначення відповідних розподілів імовірності векторів ознак [1].
Розглянемо систему розпізнавання мови побудовану на застосуванні СММ із використанням кодової книги (рис. 7).
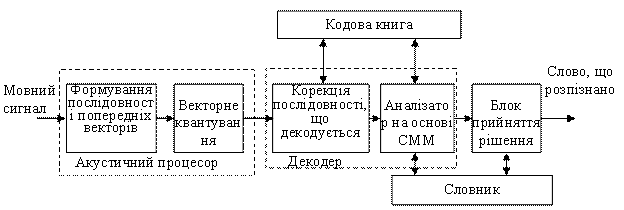 Рис. 7 Система розпізнавання мови на
основі СММ
Рис. 7 Система розпізнавання мови на
основі СММ
Акустичний процесор виконує задачі дискретизації, попередньої обробки й виділення характерних ознак, тобто перетворює акустичний мовний сигнал в набір характеристичних векторів, що в наступному використовуються для побудови кодової книги, навчання СММ та безпосередньо розпізнавання.
Декодер здійснює розрахунок найбільш
імовірних слів, що відповідають послідовності кластерів, які отримані на виході
акустичного процесору. При цьому кожному слову відповідає власна марківський
ланцюг з ![]() станів
і вимог переходу між ними. Робота декодер здійснюється в безпосередньому
звернені до кодової книги (набору обмеженої кількості еталонних ознак, що є
словами кодової книги), згідно алгоритму розпізнавання. В якості алгоритму
розпізнавання обрано алгоритм послідовного декодування із поверненнями, що
реалізує максимум правдоподібності. Ймовірності символів, що спостерігаються,
визначаються функцією розподілу, в той час як імовірності переходу із одного
стану в інший задаються дискретними значеннями з матриці розподілу. Процес
розпізнавання полягає на застосуванні алгоритму Вітербі (цей алгоритм є
варіантом методу динамічного програмування для ланцюгів Маркова, він
складається з прямого та зворотного проходів).
станів
і вимог переходу між ними. Робота декодер здійснюється в безпосередньому
звернені до кодової книги (набору обмеженої кількості еталонних ознак, що є
словами кодової книги), згідно алгоритму розпізнавання. В якості алгоритму
розпізнавання обрано алгоритм послідовного декодування із поверненнями, що
реалізує максимум правдоподібності. Ймовірності символів, що спостерігаються,
визначаються функцією розподілу, в той час як імовірності переходу із одного
стану в інший задаються дискретними значеннями з матриці розподілу. Процес
розпізнавання полягає на застосуванні алгоритму Вітербі (цей алгоритм є
варіантом методу динамічного програмування для ланцюгів Маркова, він
складається з прямого та зворотного проходів).
Переваги алгоритму: він дозволяє досягти компромісу між об'ємом пам’яті, що вимагається й кількістю обчислень, за рахунок визначення на кожному кроці функції правдоподібності та порівняння її з граничним значенням. Тестування таких систем із словником з 50 слів, що промовляються різними дикторами, які не приймали участі в процесі настройки та навчання системи, доводить вірогідність розпізнання не нижче 78%.
Нейронні мережі.
Метод використовує ймовірносно-мережеві моделі ухвалення рішення, у тому числі нейронні мережі. При даному підході будь-який мовний сигнал можна представити як вектор у параметричному просторі, потім цей вектор може бути зафіксовано у нейромережі. Одна з моделей нейромереж, що навчаються без учителя – це карта ознак Кохонена, що самоорганізується. У ній для множини сигналів формуються нейронні ансамблі, що представляють ці сигнали. Цей алгоритм має здатність до статичного усереднення, тобто вирішується проблема з варіантністю мови. Багато нейромережевих алгоритмів здійснюють рівнобіжну обробку інформації, тобто одночасно обробляють усі нейрони. Тим самим вирішується проблема зі швидкістю розпізнавання – звичайний час роботи нейромережі складає декілька ітерацій. На основі нейромереж легко будуються ієрархічні багаторівневі структури, при цьому зберігається їхня прозорість (можливість їхнього розподільного аналізу). Використання систем нейромереж, що самоадаптуються, дозволяє уникнути недоліків "некерованої" класифікації, що виявляються при використанні несупервизорних нейромережевих алгоритмів. Нижче на рис.8 приведена структура системи з використанням мереж із самостійною адаптацією для розпізнавання слів людської мови, розробленої в Красноярськом інституті біофізики Російської Академії Наук [6].
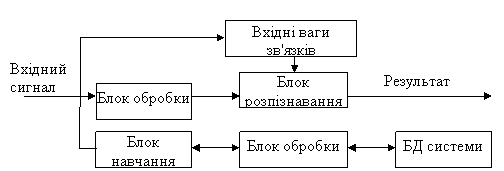
Рис. 8 Загальна схема СРМ з використанням нейромереж
Блок розпізнавання і блок навчання містять по дві нейромережі кожний. В цій роботі розглядається можливість побудови комплексу нейроних мереж з самостійною адаптацією, що навчаються по кінцевому результату.
Нейромережа має досить просту структуру і складається з трьох рівнів: вхідний шар, символьний шар та ефекторний шар. Кожний нейрон наступного шару пов’язан з усіма нейронами попереднього шару. Функція передачі в усіх шарах є лінійною; а вхідному шарі моделюється конкуренція.
Навчання системи в цілому складається з трьох етапів. Спочатку системі пред'являються тільки зразки звуків, при цьому на вхідному шарі формуються нейронні ансамблі, ядрами яких є ці зразки. Потім пред'являються звуки і відповідні їм символи алфавіту, при цьому здійснюється асоціація нейронів вхідного рівня з нейронами символьного рівня. На останньому етапі система навчається й адаптується.
Перспективи розвитку мовного інтерфейсу.
Сьогодні самими складними елементами побудови систем розпізнавання мови є насамперед алгоритми відтворення послідовності вимовлених слів, визначення ефективної інваріантної акустичної моделі й формування мовних моделей для тих, чи інших мов, що потребує багаторічної праці спеціалістів різних галузей науки: інженерів-акустиків, дослідників мовних технологій, нейрофізіологів, лінгвістів.
На акустичному рівні дуже важливим є якісне й водночас досить компактне представлення звукового сигналу в багатомірному просторі ознак, що містять значиму для розпізнавання інформацію. Для побудови векторів ознак використовуються методи спектрального аналізу (лінійне передбачення мови, гомоморфний аналіз), однак вони мають ряд недоліків. Для створення акустичної моделі сигналу пропонується використання вейвлетного базису , що має ряд переваг перед перетворенням Фур'є: локалізація в тимчасовій і частотній області, можливість масштабного перетворення і зсувів, відображення локальних особливостей сигналу. Вейвлет-перетворення може використовуватися як для акустичного представлення сигналів, так і для їхньої фільтрації.
Нейромережі дуже якісно й швидко виконують задачі класифікації, за рахунок паралельної обробки усіх нейронів. Можна отримати кореляцію інформації, що надходить на вхід мережі (подібний процес відбувається в слуховому аналізаторі людини), чого важко досягти при використанні СММ. До переваг нейромереж можна віднести відносно простий процес навчання, можливість самонавчання та адаптації, а також можливість використання генетичних алгоритмів.
Ефективність використання статистичного підходу – схованих марківських моделей для встановлення послідовностей слів безперечна, що підтверджує історія відкриття марківських процесів (Марків розробив свою теорію аналізуючи текст твору О.С. Пушкіна „Євгеній Онєгін”). Однак існує ряд обмежень цього підходу, які можливо частково компенсувати за рахунок використання нейромереж, також можливо звузити область пошуку гіпотез.
Таким чином можна створити більш ефективну систему розпізнавання мови, об’єднавши нейромережевий підхід, сховані марківські моделі й вейвлетне перетворення, використовуючи їх переваги.
Треба зазначити, особливість сприйняття мови людиною – він не все те чує, що сприймає, більшість інформації він домислює. Отже потрібно створювати системи розпізнавання мови наділені властивостями інтелекту людини. Перші кроки до цього вже робляться.
В наступному можна очікувати появу не тільки систем мовного діалогу, а й створення інтерпретаторів, спроможних вірно передати зміст й семантичне наповнення спотвореного мовного повідомлення чи інформації отриманої в умовах наявності стаціонарних й нестаціонарних перешкод.
Незважаючи на велику зацікавленість багатьох науковців дослідження й розробка мовного інтерфейсу потребує підтримки з боку державних установ і корпорацій з випуску програмного забезпечення й комп’ютерного устаткування з іншого.
Article is devoted to the decision of a problem of recognition of speech which consists in exact and effective reproduction of the made language signal. The basic types of systems of recognition of speech and approaches to their construction are considered.
1. Е.И. Бовбель, И.Э. Хейдеров. Статистические методы распознавания речи: скрытые Марковские модели //зарубежная радиоэлектроника. Успехи современной радиоэлектроники. 1998 №3, с. 45-65.
2. Плотников В.П. Речевой диалог в системах управления. –М.: Машиностроение, 1998.
3. Рабинер Р.Л. цифровая обработка речевых сигналов. – М.: Радио и связь, 1989.
4. On-line session on http: //magazin.stankin.ru/arch/h_02/automation
5. Потапова Р.К. Речевое управление роботом. –М.: Радио и связь, 1989.
6. Лалетин П.А., Ланкина Э.Г., Ланкин Ю.П., Использование сетей с самостоятельной адаптацией для распознавания слов человеческой речи// Научная сессия МИФИ-2000. II Всероссийская научно-техническая конференция «Нейроинформатика-2000». Сборник научных трудов. В 2частях. Ч.2. – М.: МИФИ, 2000. – с. 88-95
Ответы на вопросы [_Задать вопроос_]
Читайте также
Информационно-измерительные системы
Ковальов О.І. Вимірювання у процесно-орієнтованих стандартахПолякова М.В., Ищенко А.В., Худайбердин Э.И. Порогово-пространственная сегментация цветных текстурированных изображений на основе метода JSEG
Дзюбаненко А. В. Организация компьютерных систем для анализа изображений
Гордеев Б.Н., Зивенко А.В., Наконечный А.Г. Формирование зондирующих импульсов для полиметрических измерительных систем
Богданов А.В., Бень А.П., Хойна С.И. Релаксация обратного тока диодов Шоттки после их магнитно-импульсной обработки (МИО)
Тверезовский В.С., Бараненко Р.В. Проектирование измерителя добротности варикапов
Тверезовский В.С., Бараненко Р.В. Оптимизированная модель измерителя доб-ротности варикапов
Руднєва М.С., Кочеткова О.В., Задорожній Р.О. Принципи побудови оптимальної структури інформаційно-вимірювальної системи геометричних розмірів об’єктів в діапазоні від 1 нм до 1000 нм
Биленко М.С., Рожков С.А., Единович М.Б. Идентификация деформаций пе-риодических структур с использованием систем технического зрения
Рашкевич Ю.М., Ковальчук А.М., Пелешко Д.Д. Афінні перетворення в модифікаціях алгоритму RSA шифрування зображень
Дидык А.А., Фефелов А.А, Литвиненко В.И., Шкурдода С.В., Синяков Ф. В. Классификация масс-спектров с помощью кооперативного иммунного алгоритма
Клименко А.K. Обратная модель для решения задач в системах с многосвязными динамическими объектами
Завгородній А.Б. Порівняльне дослідження твердотільних і рідиннофазних об'єктів методом газорозрядної візуалізації
Голощапов С.С., Петровский А.В., Рожко Ж.А., Боярчук А.И. Измерение доб-ротности колебательного контура на основе метода биения частот
Кириллов О.Л., Якимчук Г.С. Диагностирование критерия безопасности при заполнении замкнутых объемов СПЖ косвенным методом
Долина В.Г. Проблеми підвищення точності рефрактометра на основі прозорих порожнистих циліндрів.
Самков О.В., Захарченко Ю.А. Застосування алгоритму клонального відбору для побудови планів модернізації авіаційної техніки
Попов Д.В. Метод формування регламентів технічного обслуговування повітряних суден
Казак В.М., Чорний Г.П., Чорний Т.Г. Оцінювання готовності технічних об’єктів з урахуванням достовірності їх контролю
Тверезовский В.С., Бараненко Р.В. Технические аспекты проектирования цифрового измерителя добротности варикапов
Тверезовский В.С., Бараненко Р.В. Технические аспекты проектирования устройства для разбраковки варикапов по емкостным параметрaм и добротности
Сосюк А.В. Інтелектуальний автоматизований контроль знань в системах дистанційного навчання
Соколов А.Є. Деякі аспекти систезу комп’ютеризованої адаптивної системи навчання
Полякова М.В., Волкова Н.П., Іванова О.В. Сегментація зображень стохастичних текстур амплітудно-детекторним методом у просторі вейвлет-перетворення
Луцкий М.Г., Пономаренко А.В., Филоненко С.Ф. Обработка сигналов акустической эмиссии при определении положения сквозных дефектов
Литвиненко В.И., Дидык А.А., Захарченко Ю.А. Компьютерная система для решения задач классификации на основе модифицированных иммунных алгоритмов
Лубяный В.З., Голощапов С.С. Прямоотсчетные измерители расхождений емкостей
Беляев А.В. Построение навигации для иерархических структур в WEB-системах и системах управления WEB-сайтом
Терновая Т.И., Сумская О.П., Слободянюк И.И., Булка Т.И. Контроль качества тканей специального назначения с помощью автоматических систем.
Шеховцов А.В. Інформаційний аспект: розпізнавання образів індивідуума.
Полякова М.В. Определение границ сегмента упорядоченной текстуры на изображении с однородным фоном с помощью многоканального обнаружения пачки импульсов.
Литвиненко В.И. Прогнозирования нестационарных временных рядов с помощью синтезируемых нечетких нейронных сетей
Ковриго Ю.М., Мисак В.Ф., Мовчан А.П., Любицький С.В. Автоматизована система діагностики генераторів електростанцій
Браїловський В.В., Іванчук М.М., Ватаманюк П.П., Танасюк В.С. Керований детектор імпульсного ЯКР спектрометра
Забытовская О.И. Построение функции полезности по экспериментальным данным.
Шиманські З. Апаратні засоби сегментації мовного сигналу
Хобин В.А., Титлова О.А. К вопросу измерения парожидкостного фронта в дефлегматоре абсорбционно-диффузионной холодильной машины (АДХМ)
Фефелов А. А. Использование байесовских сетей для решения задачи поиска места и типа отказа сложной технической системы
Слань Ю. М., Трегуб В. Г. Оперативна нейромережна ідентифікація складних об’єктів керування
Ролик А.И. Модель управления перераспределением ресурсов информационно-телекоммуникационной системы при изменении значимости бизнес-процессов
Кириллов О.Л., Якимчук Г.С., Якимчук С.Г. Изучение электрического поля с помощью датчика измерителя электростатического потенциала на модели замкнутого металлического объема
Грицик В.В. Застосування штучних нейронних мереж при проектуванні комп’ютерного зору.
Гасанов А.С. Информационные технологии построения систем прогнозирования отказов
Шеховцов А.В., Везумский А.К., Середа Е.С. Алгоритм сжатия информации без потерь: модифицированный алгоритм LZ77
Ходаков В.Е., Жарикова М.В., Ляшенко Е.Н. Методы и алгоритмы визуализации пространственных данных на примере моделирования распространения лесных пожаров.
Полякова М.В., Крылов В.Н. Обобщённые масштабные функции с компактным носителем в задаче сегментации изображений упорядоченных текстур. – C. 75 – 84.
Полторак В.П., Дорогой Я.Ю. Система распознавания образов на базе нечеткого нейронного классификатора.
Литвиненко В.И. Синтез радиально-базисных сетей для решения задачи дистанционного определения концентрации хлорофилла.
Бражник Д.А. Управление совмещением изображения объекта в сцене и эталонного изображения.
Бабак В.П., Пономаренко А.В. Локализация места положения сквозных дефектов по сигналам акустической эмиссии.
Мороз В. В. R-D проблема и эффективность систем сжатия изображений.
Крылов В.Н., Полякова М.В., Волкова Н.П. Контурная сегментация в пространстве гиперболического вейвлет-преобразования с использованием математической морфологии.
Квасников В.П., Баранов А.Г. Анализ влияния дестабилизирующих факторов на работу биканальной координатно-измерительной машины.
Казак В.М., Гальченко С.М., Завгородній С.О. Аналіз можливості застосування імовірнісних методів розпізнавання для виявлення пошкоджень зовнішнього обводу літака.
Тищенко И.А., Лубяный В.З. Управление коммутационными процессами в интегрированных сетях связи.
Корниенко-Мифтахова И.К.,Филоненко С.Ф. Информационно-измерительная система для анализа характеристик динамического поведения конструкций.
Тверезовский В.С., Бараненко Р.В. Модель измерителя емкости с линейной шкалой измерений.
Полякова М.В., Крылов В.Н. Мультифрактальный метод автоматизированного распознавания помех на изображении.
Рожков С.О., Федотова О.М. Алгоритм розпізнавання дефектів тканин для автоматичної системи контролю якості.
Бражник Д.А. Использование проективного преобразования для автоматизации обнаружения объектов.