УДК 681
ИНТЕЛЕКТУАЛЬНЫЙ АНАЛИЗ ДАННЫХ
И УПРАВЛЕНИЕ ПРОЦЕССАМИ В ТУРИСТИЧЕСКОЙ СФЕРЕ
Кукина А.В., Чёрный С.Г.
Введение. Современный уровень развития аппаратных и программных средств с некоторых пор сделал возможным повсеместное ведение баз данных оперативной информации на разных уровнях управления. В процессе своей деятельности промышленные предприятия, корпорации, ведомственные структуры, органы государственной власти и управления накопили большие объемы данных. Они хранят в себе большие потенциальные возможности по извлечению полезной аналитической информации, на основе которой можно выявлять скрытые тенденции, строить стратегию развития, находить новые решения.[1] В последние годы в мире оформился ряд новых концепций хранения и анализа корпоративных данных: хранилища данных, или склады данных (Data Warehouse); оперативная аналитическая обработка (On-Line Analytical Processing, OLAP); интеллектуальный анализ данных - ИАД (Data Mining).
Постановка задачи. Оперативная аналитическая обработка и интеллектуальный анализ данных - две составные части процесса поддержки принятия решений. На сегодняшний день большинство прогрессивных информационно-аналитических систем заостряет внимание только на обеспечении доступа к многомерным данным, а большинство средств интеллектуального анализа данных, которые функционируют в сфере закономерностей, имеют дело с одномерными перспективами данных. Для более продуктивной формы деятельности, необходимо произвести «склеивание» этих двух видов анализа, то есть разрабатываемые в этой среде системы должны фокусироваться не только на доступе, но и на поиске закономерностей в базах.
Анализ последних достижений и публикаций. Построение информационно-аналитических систем, с аналитически-интеллектуальный анализом данных, который заложен в основу проектируемой системы - является одной из актуальных тем при проектировании современных экономических, биологических и др., систем в современном информационном обществе. Разработки в данной области внедряются в крупные программные продукты, такие как OLAP-модели, ROLAP, MOLAP, CASE-технологии и многое другое, реализация данных продуктов среды находят все новое и новое применение в различных отраслях.[2]
Сегодняшняя ситуация с пониманием того, зачем нужны неспециализированные универсальные средства аналитического доступа к данным и репортинга достигла той стадии, которая была лет 10 - 15 назад на рынке СУБД.[3] В тот момент в основном сложилось общее представление о том, какая функциональность требуется от серверов баз данных, чтобы удовлетворить общие потребности в хранении данных и создать такие, не специализированные на какой-то одной области знаний СУБД. Тогда, появление хороших систем СУБД дало возможность не разрабатывать систему хранения информации каждый раз заново в каждой компании, а использовать уже готовую СУБД какого-либо производителя.
К сожалению, очень немногие производители предоставляют сегодня достаточно мощные средства интеллектуального анализа многомерных данных в рамках систем OLAP. Проблема также заключается в том, что некоторые методы ИАД (байесовские сети, метод k-ближайшего соседа) неприменимы для задач многомерного интеллектуального анализа, так как основаны на определении сходства детализированных примеров и не способны работать с агрегированными данными [4].
Решение поставленной задачи. Рассмотрим в отдельности для начала формирование каждой из модели. Что позволит охарактеризовать модели и дать более комплексный анализ-заключение по объединению информационных структур моделей.
Представим на рисунке 1 многомерный интеллектуальный анализ. Проектируемую схему разобьем по блочной структуре, для большей наглядности проектировщику.
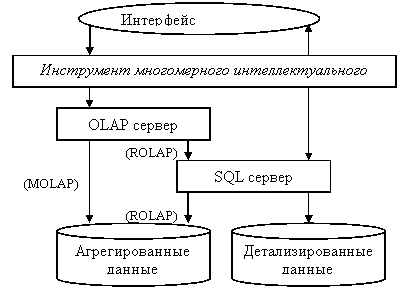 |
Рис. 1 Архитектура системы многомерного интеллектуального анализа данных
Интеллектуальный анализ данных (ИАД -(Data Mining)) - это процесс поддержки принятия решений, основанный на поиске в данных скрытых закономерностей (шаблонов информации). При этом накопленные сведения автоматически обобщаются до информации, которая может быть охарактеризована как знания. Если систематизировать структуру данного процесса, тот в общем случае ИАД состоит из трёх стадий [5] (рис. 2):
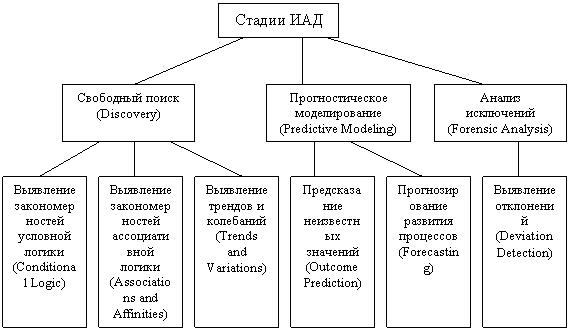 |
Рис. 2 Стадии процесса интеллектуального анализа данных
1) выявление закономерностей (свободный поиск);
2) использование выявленных закономерностей для предсказания неизвестных значений (прогностическое моделирование);
3) анализ исключений, предназначенный для выявления и толкования аномалий в найденных закономерностях.
В явном виде выделяют промежуточную стадию проверки достоверности найденных закономерностей между их нахождением и использованием (выделение происходит не всегда).
Все методы ИАД подразделяются на две большие группы по принципу работы с исходными обучающими данными [6].
1. В первом случае исходные данные могут храниться в явном детализированном виде и непосредственно использоваться для прогностического моделирования и/или анализа исключений; это так называемые методы рассуждений на основе анализа прецедентов. Главной проблемой этой группы методов является затрудненность их использования на больших объемах данных, хотя именно при анализе больших хранилищ данных методы ИАД приносят наибольшую пользу.
2. Во втором случае информация вначале извлекается из первичных данных и преобразуется в некоторые формальные конструкции (их вид зависит от конкретного метода). Согласно предыдущей классификации, этот этап выполняется на стадии свободного поиска, которая у методов первой группы в принципе отсутствует. Таким образом, для прогностического моделирования и анализа исключений используются результаты этой стадии, которые гораздо более компактны, чем сами массивы исходных данных. При этом полученные конструкции могут быть либо "прозрачными" (интерпретируемыми), либо "черными ящиками" (нетрактуемыми). [7]
Теперь представим две эти группы и примеры входящих в них методов графически на рис. 3.
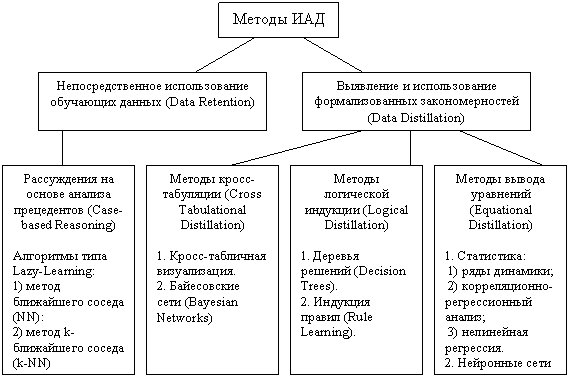
Рис. 3 Классификация технологических методов ИАД
Реляционный OLAP (ROLAP) - непосредственное использование реляционных БД в системах оперативной аналитической обработки имеет следующие достоинства.
1. В большинстве случаев корпоративные хранилища данных реализуются средствами реляционных СУБД, и инструменты ROLAP позволяют производить анализ непосредственно над ними. При этом размер хранилища не является таким критичным параметром, как в случае MOLAP.
2. В случае переменной размерности задачи, когда изменения в структуру измерений приходится вносить достаточно часто, ROLAP системы с динамическим представлением размерности являются оптимальным решением, так как в них такие модификации не требуют физической реорганизации БД.
3. Реляционные СУБД обеспечивают значительно более высокий уровень защиты данных и хорошие возможности разграничения прав доступа.
Главный недостаток ROLAP по сравнению с многомерными СУБД - меньшая производительность. Для обеспечения производительности, сравнимой с MOLAP, реляционные системы требуют тщательной проработки схемы базы данных и настройки индексов, то есть больших усилий со стороны администраторов БД. Только при использовании звездообразных схем производительность хорошо настроенных реляционных систем может быть приближена к производительности систем на основе многомерных баз данных.
Описанию схемы звезды (star schema) и рекомендациям по ее применению полностью посвящены работы [7,9,11]. Ее идея заключается в том, что имеются таблицы для каждого измерения, а все факты помещаются в одну таблицу, индексируемую множественным ключом, составленным из ключей отдельных измерений (рис. 4). Каждый луч схемы звезды задает, в терминологии Кодда, направление консолидации данных по соответствующему измерению.

Рис. 4 Пример схемы «звезды»
В сложных задачах с многоуровневыми измерениями имеет смысл обратиться к расширениям схемы звезды - схеме созвездия (fact constellation schema) и схеме снежинки (snowflake schema) [9,12]. В этих случаях отдельные таблицы фактов создаются для возможных сочетаний уровней обобщения различных измерений (рис. 5). Это позволяет добиться лучшей производительности, но часто приводит к избыточности данных и к значительным усложнениям в структуре базы данных, в которой оказывается огромное количество таблиц фактов.
Увеличение числа таблиц фактов в базе данных может проистекать не только из множественности уровней различных измерений, но и из того обстоятельства, что в общем случае факты имеют разные множества измерений. При абстрагировании от отдельных измерений пользователь должен получать проекцию максимально полного гиперкуба, причем далеко не всегда значения показателей в ней должны являться результатом элементарного суммирования. Таким образом, при большом числе независимых измерений необходимо поддерживать множество таблиц фактов, соответствующих каждому возможному сочетанию выбранных в запросе измерений, что также приводит к неэкономному использованию внешней памяти, увеличению времени загрузки данных в БД схемы звезды из внешних источников и сложностям администрирования.

|
|
Рис. 5 Пример схемы «снежинки» (фрагмент для одного измерения)
Частично решают эту проблему расширения языка SQL (операторы "GROUP BY CUBE", "GROUP BY ROLLUP" и "GROUP BY GROUPING SETS"); кроме того, авторы статей [13,15,16] предлагают механизм поиска компромисса между избыточностью и быстродействием, рекомендуя создавать таблицы фактов не для всех возможных сочетаний измерений, а только для тех, значения ячеек которых не могут быть получены с помощью последующей агрегации более полных таблиц фактов (рис. 6).
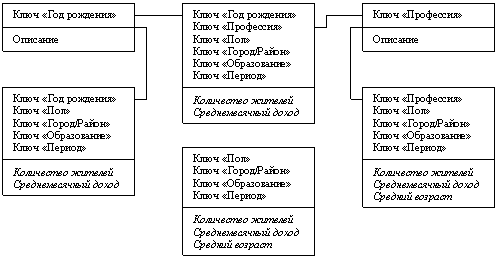
Рис. 6 Таблицы фактов для разных сочетаний измерений в запросе
В любом случае, если многомерная модель реализуется в виде реляционной базы данных, следует создавать длинные и «узкие» таблицы фактов и сравнительно небольшие и «широкие» таблицы измерений. Таблицы фактов содержат численные значения ячеек гиперкуба, а остальные таблицы определяют содержащий их многомерный базис измерений. Часть информации можно получать с помощью динамической агрегации данных, распределенных по незвездообразным нормализованным структурам, хотя при этом следует помнить, что включающие агрегацию запросы при высоконормализованной структуре БД могут выполняться довольно медленно.
Ориентация на представление многомерной информации с помощью звездообразных реляционных моделей позволяет избавиться от проблемы оптимизации хранения разреженных матриц, остро стоящей перед многомерными СУБД (где проблема разреженности решается специальным выбором схемы). Хотя для хранения каждой ячейки используется целая запись, которая помимо самих значений включает вторичные ключи - ссылки на таблицы измерений, несуществующие значения просто не включаются в таблицу фактов.
Если рассмотреть аналитические способы обработки данных - для того чтобы существующие хранилища данных способствовали принятию управленческих решений, информация должна быть представлена аналитику в нужной форме, то есть он должен иметь развитые инструменты доступа к данным хранилища и их обработки.
Очень часто информационно-аналитические системы, создаваемые в расчете на непосредственное использование лицами, принимающими решения, оказываются чрезвычайно просты в применении, но жестко ограничены в функциональности. Такие статические системы называются в литературе Информационными системами руководителя (ИСР), или Executive Information Systems (EIS) [11]. Они содержат в себе предопределенные множества запросов и, будучи достаточными для повседневного обзора, неспособны ответить на все вопросы к имеющимся данным, которые могут возникнуть при принятии решений. Результатом работы такой системы, как правило, являются многостраничные отчеты, после тщательного изучения которых у аналитика появляется новая серия вопросов. Однако каждый новый запрос, непредусмотренный при проектировании такой системы, должен быть сначала формально описан, закодирован программистом и только затем выполнен. Время ожидания в таком случае может составлять часы и дни, что не всегда приемлемо. Таким образом, внешняя простота статических СППР, за которую активно борется большинство заказчиков информационно-аналитических систем, оборачивается катастрофической потерей гибкости.
Динамические СППР, напротив, ориентированы на обработку нерегламентированных (ad hoc) запросов аналитиков к данным.
Динамические СППР могут действовать не только в области оперативной аналитической обработки (OLAP); поддержка принятия управленческих решений на основе накопленных данных может выполняться в трех базовых сферах [3].
1.Сфера детализированных данных. Это область действия большинства систем, нацеленных на поиск информации. В большинстве случаев реляционные СУБД отлично справляются с возникающими здесь задачами. Общепризнанным стандартом языка манипулирования реляционными данными является SQL. Информационно-поисковые системы, обеспечивающие интерфейс конечного пользователя в задачах поиска детализированной информации, могут использоваться в качестве надстроек как над отдельными базами данных транзакционных систем, так и над общим хранилищем данных.
2.Сфера агрегированных показателей. Комплексный взгляд на собранную в хранилище данных информацию, ее обобщение и агрегация, гиперкубическое представление и многомерный анализ являются задачами систем оперативной аналитической обработки данных (OLAP) [9,15,17]. Здесь можно или ориентироваться на специальные многомерные СУБД [7], или оставаться в рамках реляционных технологий. Во втором случае заранее агрегированные данные могут собираться в БД звездообразного вида, либо агрегация информации может производиться на лету в процессе сканирования детализированных таблиц реляционной БД.
3.Сфера закономерностей. Интеллектуальная обработка производится методами интеллектуального анализа данных (ИАД, Data Mining) [9,11,17], главными задачами которых являются поиск функциональных и логических закономерностей в накопленной информации, построение моделей и правил, которые объясняют найденные аномалии и/или прогнозируют развитие некоторых процессов.
Полная структура информационно-аналитической системы, построенной на основе хранилища данных, показана на рис. 7. В конкретных реализациях отдельные компоненты этой схемы часто отсутствуют.
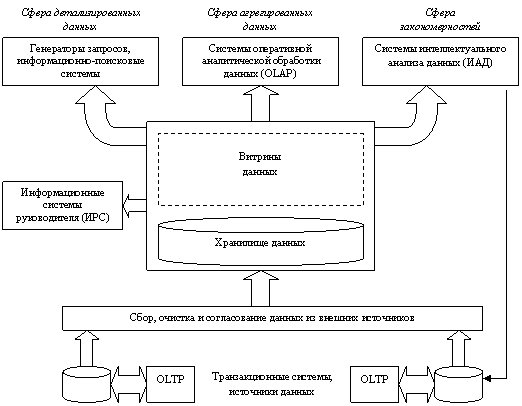 |
Рис. 7 Полная структура корпоративной информационно-аналитической системы (ИАС)
Основные результаты и выводы. В данной работе отражена технология построения моделей извлечения данных на основе уже существующих компонент, отражен механизм комплексного перехода от модели к модели в структурно-иерархическом виде путем регламентированной балансировки. Выбор различных информационно-аналитических систем очень велик, но удобно создавать информационно-аналитическую систему для конкретного предприятия, что позволяет более эффективно настроить свою работу, т.к. каждое предприятие или фирма имеет свою спецификацию, которая не ограничивается в работе при покупке готовой системы. В данной статье были реализованы основные аспекты проектирования информационно-аналитической системы, которая может быть разработана и внедрена в туристические фирмы.
The Article is dedicated to building automated systems knowledgebase on base of the using progressive information technology in themes database and development of the extraction and contributing the new information structure on base already existing models.
1. Чёрный С.Г. Информационные технологии в структуре регионального туризма / Вісник ХДТУ - №2(18), - 2003. – с.269-272.
2. Григорова А.А., Чёрный С.Г. Формирование современной информационно-аналитической системы для поддержки принятия решений / ААЭКС - №2(12), - 2003. – С. 74-77.
3. Дюк В.А. Формирование знаний в системах искусственного интеллекта: геометрический подход (ч. 4, глава 2)/В кн. Телемедицина. Новые информационные технологии на пороге XXI века. – СПб: “Анатолия”, 1998. С. 367—389.
4. Решение проблемы комплексного оперативного анализа информации хранилищ данных // С.Д. Коровкин, И.А. Левенец, И.Д. Ратманова, В.А. Старых, Л.А.Щавелев. – СУБД, 1997, №5-6, С.47-51.
5. H. Edelstein. Интеллектуальные средства анализа, интерпретации и представления данных в информационных хранилищах. // CWM, 1996, №16, с.32-35.
6. М.Альперович. Microsoft SQL Server Хранилища данных – Сегодня и завтра. // Компьютер-информ, 1997.
7. H. Edelstein. Data Mining: Exploiting the Hidden Trends in Your Data.A perspective on databases and data mining. // M. Holsheimer, M. Kersten, H Mannila and H. Toivonen. – CS-R9531, 1995.
8. М. Киселев, Е. Соломатин. Средства добычи знаний в бизнесе и финансах. // Открытые системы, 1997, №4, С. 41-44
9. P. Hagen, «Smart Personalization», The Forrester Report, Forrester Research, Cambridge, Mass., July 1999
10. P. Resnick et al., «GroupLens: An Open Architecture for Collaborative Filtering of Netnews», Proc. 1994 Computer-Supported Cooperative Work Conf., ACM Press, New York, 1994, pp. 175-186
11. U. Shardanand and P. Maes, «Social Information Filtering: Algorithms for Automating ‘Word of Mouth’», Proc. Conf. Human Factors in Computing Systems (CHI 95), ACM Press, New York, 1995, pp. 210-217
12. W. Hill et al., «Recommending and Evaluating Choices in a Virtual Community of Use», Proc. Conf. Human Factors in Computing Systems (CHI95), ACM Press, New York, 1995, pp. 194-201
13. G. Adomavicius and A. Tuzhilin, «Expert-Driven Validation of Rule-Based User Models in Personalization Applications», J. Data Mining and Knowledge Discovery, Jan. 2001, pp. 33-58
14. R. Agrawal et al., «Fast Discovery of Association Rules», Advances in Knowledge Discovery and Data Mining, AAAI Press, Menlo Park, Calif., 1996, chap. 12
15. L. Breiman et al., Classification and Regression Trees, Wadsworth, Belmont, Calif., 1984
16. G. Piatetsky-Shapiro and C.J. Matheus, «The Interestingness of Deviations», Proc. AAAI-94 Workshop Knowledge Discovery in Databases, AAAI Press, Menlo Park, Calif., 1994, pp. 25-36
17. A. Silberschatz and A. Tuzhilin, «What Makes Patterns Interesting in Knowledge Discovery Systems», IEEE Trans. Knowledge and Data Engineering, Dec. 1996, pp. 970-974
18. 17.R. Srikant, Q. Vu, and R. Agrawal, «Mining Association Rules with Item Constraints», Proc. Third Int’l Conf. Knowledge Discovery and Data Mining, AAAI Press, Menlo Park, Calif., 1997, pp. 67-73
Ответы на вопросы [_Задать вопроос_]
Читайте также
Информационно-измерительные системы
Ковальов О.І. Вимірювання у процесно-орієнтованих стандартахПолякова М.В., Ищенко А.В., Худайбердин Э.И. Порогово-пространственная сегментация цветных текстурированных изображений на основе метода JSEG
Дзюбаненко А. В. Организация компьютерных систем для анализа изображений
Гордеев Б.Н., Зивенко А.В., Наконечный А.Г. Формирование зондирующих импульсов для полиметрических измерительных систем
Богданов А.В., Бень А.П., Хойна С.И. Релаксация обратного тока диодов Шоттки после их магнитно-импульсной обработки (МИО)
Тверезовский В.С., Бараненко Р.В. Проектирование измерителя добротности варикапов
Тверезовский В.С., Бараненко Р.В. Оптимизированная модель измерителя доб-ротности варикапов
Руднєва М.С., Кочеткова О.В., Задорожній Р.О. Принципи побудови оптимальної структури інформаційно-вимірювальної системи геометричних розмірів об’єктів в діапазоні від 1 нм до 1000 нм
Биленко М.С., Рожков С.А., Единович М.Б. Идентификация деформаций пе-риодических структур с использованием систем технического зрения
Рашкевич Ю.М., Ковальчук А.М., Пелешко Д.Д. Афінні перетворення в модифікаціях алгоритму RSA шифрування зображень
Дидык А.А., Фефелов А.А, Литвиненко В.И., Шкурдода С.В., Синяков Ф. В. Классификация масс-спектров с помощью кооперативного иммунного алгоритма
Клименко А.K. Обратная модель для решения задач в системах с многосвязными динамическими объектами
Завгородній А.Б. Порівняльне дослідження твердотільних і рідиннофазних об'єктів методом газорозрядної візуалізації
Голощапов С.С., Петровский А.В., Рожко Ж.А., Боярчук А.И. Измерение доб-ротности колебательного контура на основе метода биения частот
Кириллов О.Л., Якимчук Г.С. Диагностирование критерия безопасности при заполнении замкнутых объемов СПЖ косвенным методом
Долина В.Г. Проблеми підвищення точності рефрактометра на основі прозорих порожнистих циліндрів.
Самков О.В., Захарченко Ю.А. Застосування алгоритму клонального відбору для побудови планів модернізації авіаційної техніки
Попов Д.В. Метод формування регламентів технічного обслуговування повітряних суден
Казак В.М., Чорний Г.П., Чорний Т.Г. Оцінювання готовності технічних об’єктів з урахуванням достовірності їх контролю
Тверезовский В.С., Бараненко Р.В. Технические аспекты проектирования цифрового измерителя добротности варикапов
Тверезовский В.С., Бараненко Р.В. Технические аспекты проектирования устройства для разбраковки варикапов по емкостным параметрaм и добротности
Сосюк А.В. Інтелектуальний автоматизований контроль знань в системах дистанційного навчання
Соколов А.Є. Деякі аспекти систезу комп’ютеризованої адаптивної системи навчання
Полякова М.В., Волкова Н.П., Іванова О.В. Сегментація зображень стохастичних текстур амплітудно-детекторним методом у просторі вейвлет-перетворення
Луцкий М.Г., Пономаренко А.В., Филоненко С.Ф. Обработка сигналов акустической эмиссии при определении положения сквозных дефектов
Литвиненко В.И., Дидык А.А., Захарченко Ю.А. Компьютерная система для решения задач классификации на основе модифицированных иммунных алгоритмов
Лубяный В.З., Голощапов С.С. Прямоотсчетные измерители расхождений емкостей
Беляев А.В. Построение навигации для иерархических структур в WEB-системах и системах управления WEB-сайтом
Терновая Т.И., Сумская О.П., Слободянюк И.И., Булка Т.И. Контроль качества тканей специального назначения с помощью автоматических систем.
Шеховцов А.В. Інформаційний аспект: розпізнавання образів індивідуума.
Полякова М.В. Определение границ сегмента упорядоченной текстуры на изображении с однородным фоном с помощью многоканального обнаружения пачки импульсов.
Литвиненко В.И. Прогнозирования нестационарных временных рядов с помощью синтезируемых нечетких нейронных сетей
Ковриго Ю.М., Мисак В.Ф., Мовчан А.П., Любицький С.В. Автоматизована система діагностики генераторів електростанцій
Браїловський В.В., Іванчук М.М., Ватаманюк П.П., Танасюк В.С. Керований детектор імпульсного ЯКР спектрометра
Забытовская О.И. Построение функции полезности по экспериментальным данным.
Шиманські З. Апаратні засоби сегментації мовного сигналу
Хобин В.А., Титлова О.А. К вопросу измерения парожидкостного фронта в дефлегматоре абсорбционно-диффузионной холодильной машины (АДХМ)
Фефелов А. А. Использование байесовских сетей для решения задачи поиска места и типа отказа сложной технической системы
Слань Ю. М., Трегуб В. Г. Оперативна нейромережна ідентифікація складних об’єктів керування
Ролик А.И. Модель управления перераспределением ресурсов информационно-телекоммуникационной системы при изменении значимости бизнес-процессов
Кириллов О.Л., Якимчук Г.С., Якимчук С.Г. Изучение электрического поля с помощью датчика измерителя электростатического потенциала на модели замкнутого металлического объема
Грицик В.В. Застосування штучних нейронних мереж при проектуванні комп’ютерного зору.
Гасанов А.С. Информационные технологии построения систем прогнозирования отказов
Шеховцов А.В., Везумский А.К., Середа Е.С. Алгоритм сжатия информации без потерь: модифицированный алгоритм LZ77
Ходаков В.Е., Жарикова М.В., Ляшенко Е.Н. Методы и алгоритмы визуализации пространственных данных на примере моделирования распространения лесных пожаров.
Полякова М.В., Крылов В.Н. Обобщённые масштабные функции с компактным носителем в задаче сегментации изображений упорядоченных текстур. – C. 75 – 84.
Полторак В.П., Дорогой Я.Ю. Система распознавания образов на базе нечеткого нейронного классификатора.
Литвиненко В.И. Синтез радиально-базисных сетей для решения задачи дистанционного определения концентрации хлорофилла.
Бражник Д.А. Управление совмещением изображения объекта в сцене и эталонного изображения.
Бабак В.П., Пономаренко А.В. Локализация места положения сквозных дефектов по сигналам акустической эмиссии.
Мороз В. В. R-D проблема и эффективность систем сжатия изображений.
Крылов В.Н., Полякова М.В., Волкова Н.П. Контурная сегментация в пространстве гиперболического вейвлет-преобразования с использованием математической морфологии.
Квасников В.П., Баранов А.Г. Анализ влияния дестабилизирующих факторов на работу биканальной координатно-измерительной машины.
Казак В.М., Гальченко С.М., Завгородній С.О. Аналіз можливості застосування імовірнісних методів розпізнавання для виявлення пошкоджень зовнішнього обводу літака.
Тищенко И.А., Лубяный В.З. Управление коммутационными процессами в интегрированных сетях связи.
Корниенко-Мифтахова И.К.,Филоненко С.Ф. Информационно-измерительная система для анализа характеристик динамического поведения конструкций.
Тверезовский В.С., Бараненко Р.В. Модель измерителя емкости с линейной шкалой измерений.
Полякова М.В., Крылов В.Н. Мультифрактальный метод автоматизированного распознавания помех на изображении.
Рожков С.О., Федотова О.М. Алгоритм розпізнавання дефектів тканин для автоматичної системи контролю якості.
Бражник Д.А. Использование проективного преобразования для автоматизации обнаружения объектов.